An Introduction To Buffer Overflow #2: Code Execution in RAM


Welcome to Part Two of my series of Buffer Overflow. If you haven't already, go and check out my first post on the subject buffer overflow #1, it makes for a good introduction to the subject and covers the basics before we get to this second part. Lets jump right in!
In this post I will focus on how a program is being executed in the RAM and with this you will understand that stack is nothing just a portion of RAM that is being used as the stack for the program.
So you might be wondering, "Ok cool, this is buffer and it overflows. But how does a buffer look like in a program and how can you exploit in a program". A buffer is just a memory section which is used to store our data and it usually follows Stack data structure.
What Does a Stack Look Like in a Program?
Lets understand this with an example, but before you need to know the following:
- The
mainfunction is called when an operating system executes the program. - RIP is called the Instruction Pointer, it holds the address of next instruction to be executed. It is not directly changed by programmer but can be altered by adding conditionals or function calls.
- Caller function is the function that calls another function.
- Callee function is the function which is being called by the caller function.
Let's take an example of the following code:

function_1();Now the RIP will be pointing to function_1(); address.

After the first instruction, int i = 42; it calls function_2
Transferring the point of execution aka value of RIP to function_2 with an argument.

The first line in function_2 is returns.
Now RIP will point to the next instruction of caller function (function_1) by popping out the address of function_2.

function_1 next instruction is return, so now RIP will be pointing to the next instruction in callee function i.e main

And it executes the main function's body until it ends.
Each time a new function is called, a frame of stack is being created for the function where it can hold it's local values and all. For example, in case function_1, int i was only accessible in that scope only, so to avoid conflicts, a local chunk of memory (stack frame) is created or every function that has been called. And during the return, it is then destroyed.
The key concept of exploiting buffer overflow is to overwrite RIP value with our malicious function in order to take control of the system.
Code Execution in RAM
Any program that is being executed is known a process. A process has two main things
- Code → the set of instructions to be executed by the CPU
- Data → information needs to be processed while the process execution
When a process is started, OS allocates a Process Address Space (aka Virtual Address Space). And then program’s code and data are stored in specific area of this memory location called Segments, as shown below
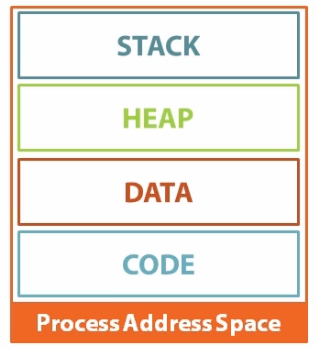
The 4 Segments
- Code : The segment holding process executable (binary file executed).
- Data : The information that is to be processed.
- Heap : It is pool for dynamic initialisation of variables.
- Stack : Its a data structure used to store multiple data items in a specific order of LIFO. All statically initialised variables are stored here.
All the data which is defined at compile time, is initialized in the stack and the other data (like pointer, linked lists) which is defined at run time and are of variable size, is initialized in the heap.
[READ MORE ON COMPILE TIME VS RUNTIME]
As you can see it is easy to overflow the stack as compared to heap. However both of them can be overflown, but in case of stack, the size seems to be fixed.
In stack, the operations are usually done by a special pointer called Stack Pointer (SP). It is a type of reserved CPU register that points to the last address of stack block in the memory. To PUSH the data, it must point the top most block of the stack and then data will be pushed. Or simply, increase the pointer value before pushing a value.
Generally the stack grows downwards, but in this case I will show an inverted growth of the stack. Suppose you want to push DATA12 in the stack the operation would go like this
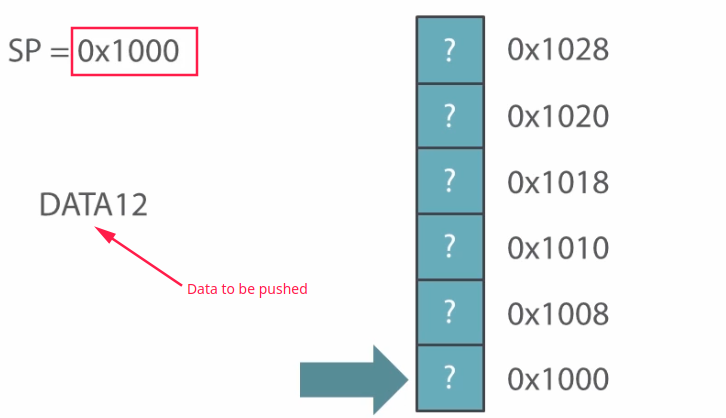
Now, After pushing some data to the stack:
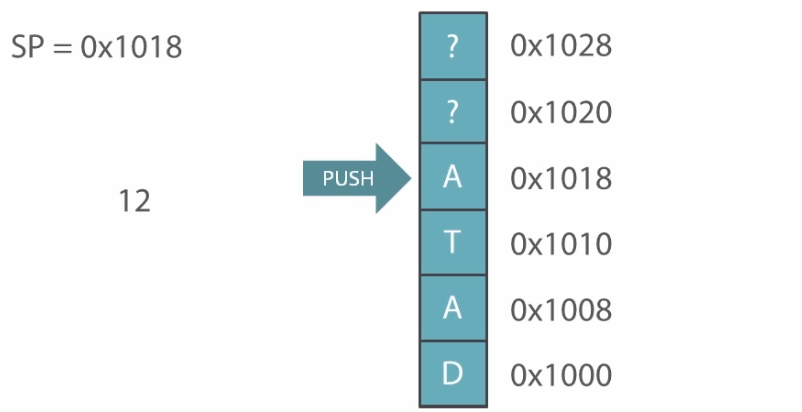
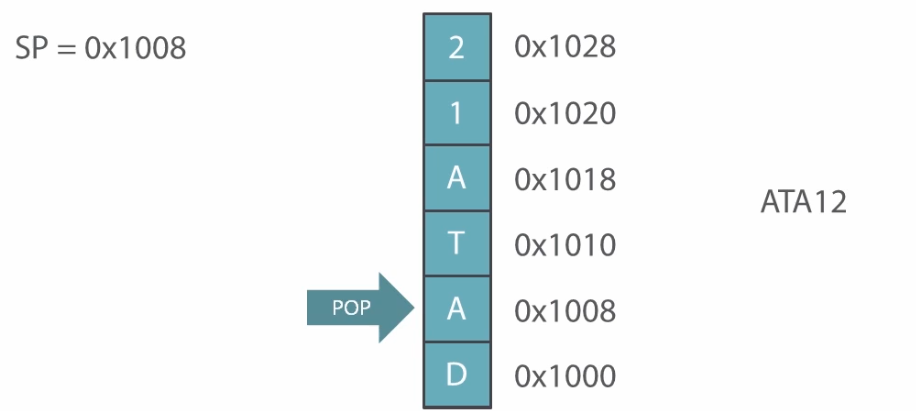
Popping the data will not make stack block empty. It will simply reduce the stack pointer value and stack will not point at the popped value anymore.
The new value if pushed will overwrite the previous data in the block.
I hope that this clears up your understanding around the subject, if you have any questions at all feel free to contact me on Twitter using @TBhaxor.
