Deep Learning & Cybersecurity: Part 3 of 5 - Data Gathering
Part 3 of our Cyber Deep Learning series where we talk about the most crucial part of any machine learning project: Data Gathering.


This is the third article of our Deep Learning and Cybersecurity series, and we will talk about one of the most crucial parts at the core of almost any machine learning project: Data Gathering.
Let's say you work for an investigation unit, and you are flooded by dozens, centuries, if not thousands of lists of links of hidden services, each of them being a potential place where to look for to find new pieces of work.
Unfortunately, the darknet is not only about escaping censorship and free-speech assembly. Arms dealers and pedo-pornographic websites are among the types of service you can find on hidden services, and cyber criminality specialists are trying to tackle this issue.
As of now, specialized units can only mitigate a tiny portion of illegal activities related to unlawful, pornographic contents or weapon selling. What if it would be possible to detect hidden services related to unlawful domains automatically? Without having to visit them manually, we can imagine the following approach resumed in the next steps :
- Gather a list of labeled hidden services to train our algorithm, this part is actually straightforward as there as thousands of darknet archives, in our next article we will use Gwern archives.
- Train our algorithm using NLP classifiers to predict if a hidden service is related to illegal activity.
- Automatically scrap hidden services and deploy our algorithm to verify if it is associated with some criminal activity.
In our next article, we will develop more about the first part. Now let's imagine we already have our trained algorithm and want to test it on hidden services, we need an efficient scraping engine that takes hidden services links as an input and gives us their text contents as an output. We will later use these outputs to evaluate our prediction algorithm and make sure these websites are not related to any illegal activities. If our classifier is powerful enough, we will be able to classify and filter hidden services, thus gaining a lot of time in our investigation.
Scrape Hidden Services Using Python, Stem, Tor, & Privoxy
We will use Python, Stem Python package, Tor, and Privoxy. Stem is a Python controller library that allows applications to interact with Tor and Privoxy is a non-caching web proxy. Make sure you have Python installed, as this article does not cover this part.
Installation
Before you run the scraper, make sure the following things are done correctly:
- Run tor service
sudo service tor start
orbrew services tor startfor MacOS users - Set a password for tor
tor --hash-password "my_password"and do not forget to include it in your python scripts - Modify the value in
scrapper.py - Go to /etc/tor/torrc and uncomment - ControlPort 9051 , you may consider accessing torrc config file using
sudo nano torrcto be able to save it
Privoxy setup
- Install privoxy
sudo apt-get install privoxy
orbrew install privoxyfor MacOS users - Change your privoxy config to get access to Tor Network
cd /to go to root directory thencd /etc/privoxy - Open your config file
nano config - Uncomment following line
forward-socks5 / localhost:9050 - Restart privoxy to load changes
sudo /etc/init.d/privoxy restartorbrew services restart privoxyfor MacOS users
Deployment
- Clone the git directory, create your virtualenv and install requirements by running the following commands :
git clone https://github.com/jct94/qt_blog_onion-scraper.git
pip install virtualenv
virtualenv yourenv
source yourenv/bin/activate
pip install -r requirements.txt
Now you are ready to start scraping, you can add hidden services in onions.txt file
- Run the scrapper using python3
python3 scrapper.py
You should get the following screen :
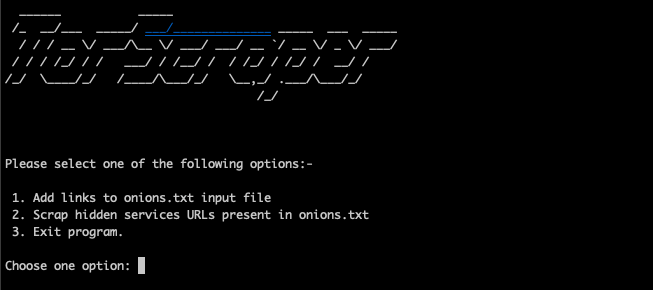
Choose option number 2, and press enter, your scrapping engine is now running, and you should have the following output :
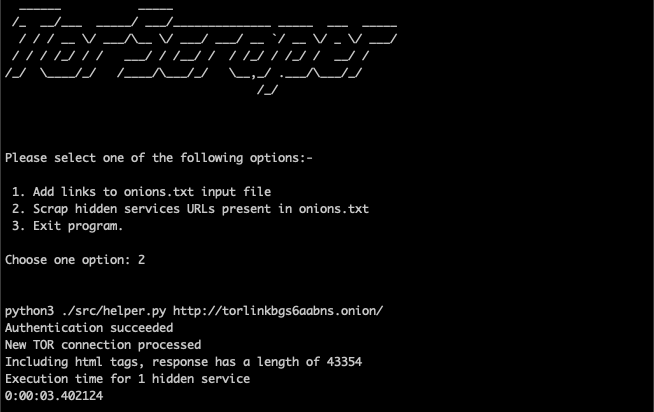
Note that for the purpose of the article, 'onions.txt' file only contains one link.
Our scraping engine saves the HTML response in the /output folder. In our next article, we will train an NLP algorithm on DarkNet archives and predict if our scraped hidden services are related to illegal or criminal activity.
[GitHub link related to this article](https://github.com/jct94).
