Deep Learning & Cybersecurity: Part 2
The intersection of deep learning and cybersecurity, featuring two famous cyber attacks and their machine learning applications.

We know very well what type of cyberattacks are the most famous, and many of them have a very well known mechanism. In fact, most successful exploits often involve a substantial part of social engineering and common-sense. Indeed, the success of many attacks involving password cracking depends on hacker’s ability to get the best out of password-leak related data, and find some patterns within the amount of leaked and noisy logs.
Natural language processing tools can be of great help for information retrieval tasks. We will also explore the use of classification algorithms to detect suspicious activity on a network and eventually mitigate the Distributed Denial of Service attack.
This is the second article of our series on Deep Learning and Cybersecurity, if you have not read the first article yet you can check it out here.
1. Keylogger attack:
A keylogger is a malicious piece of code that records the key sequence and strokes of your keyboard into a log file on your own machine. These log files can contain any type of confidential information. Also known as keyboard spying, the keylogger can be either software or hardware based.
While software-based keyloggers target the programs installed on a computer, hardware devices target keyboards, electromagnetic emissions, smartphone sensors, and can be designed as a side-channel attack. The first keylogging side-channel attack was discovered over 50 years ago when Bell Laboratory researchers noticed an electromagnetic spike emanating from a teletype terminal. This spike, emitted upon each keypress, enabled up to 75% of plaintext communications to be recovered in field conditions. We will tackle this type of attack in a dedicated article.
Here is a possible malicious NLP application. Logs are, by nature, noisy files and slow down information retrieval. Keylogger attackers are looking for valuable information within dirty and useless log lines. We can imagine a pre-trained NER or Word2Vec on entities of interests such as address, e-mail, credit card number, pet’s name, social security number.
Word2Vec is a group of language-modeling algorithms used to produce word-embeddings, word-embedding is the generic name used to describe NLP-related feature learning. In other words, words, sentences, texts are unstructured data that do not have any vectorial representations we can use as an input for any treatment. A word-embedding algorithm receives a list of words in input, and give their mathematical representation in output. We can represent them as a cloud of words:
Word2Vec takes as its input a large text corpus and vectorizes it using a shallow neural network. The output is a vocabulary with their vectorial representation. Words with similar meanings spatially occur within close proximity. Mathematically this is measured by cosine similarity, where total similarity is expressed as a 0-degree angle while no similarity is expressed as a 90-degree angle.
During training, every word is associated with a vector using context-enhancing neural network architecture of word2vec. Consequently, the vocabulary and the visual cloud of words created by Word2Vec can be used directly to create a similarity between words. These similarities are backed by a mathematic formula using cosine similarity, and a rigorous vectorial representation, Word2Vec made a perfectly intelligible probabilistic matrix out of an unstructured list of word. Now, how can we apply it on the output of a malicious keylogging algorithm?

The first cloud of words seems to be related to authentication and password, constraining the scope of the research and making the search of credentials easier. Please note that we are only talking about unsupervised-learning, deep language-modeling tools, and simple similarity measures.
There is no study to evaluate the use of NLP tools by black-hat hackers, but generative adversarial neural networks have been widely used to generate deep-fake content, and text-generation algorithms are employed by government-ruled hacking teams to flood social network of fake news.
2. Distributed Denial of Service.
DDoS is a hacking technique to take down a site or server by flooding that site or server with a lot of traffic that the server is unable to process. The attacker floods the targeted machine with tons of requests to overwhelm the resources. Even though advanced Machine Learning techniques have been adopted for DDoS detection, the attack remains a major threat of the Internet. According to the forecast of the Cisco Visual Networking Index (VNI), DDoS incidents will reach up to 17 million in 2020. This cyber threat continues to grow, even with the development of new protection technologies.
Developing mechanisms to detect this threat is a current challenge in network security, and machine learning seems a natural candidate. The research literature is full of great articles testing unsupervised and supervised methods for mitigating this type of attack. Datasets are built using network traces and can be tricky to gather as it exists a dozen of type of DDoS attacks, such as DNS amplification and flood, HTTP flood, ping flooding.
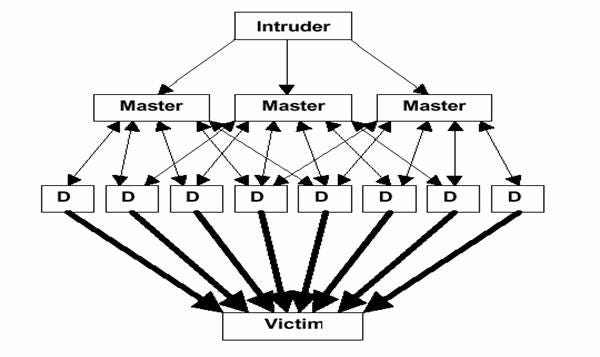
For DDoS attacks, hackers use botnets and zombie computers to flood your system with request packets. With each passing year, as the malware and types of hackers keep getting advanced, the size of DDoS attacks keeps getting increasing. How can machine learning help mitigate this type of attack?
Network-related attacks are more suited to machine learning applications as they are associated with traces and packets, making possible the creation of dataset, including labeled one for supervised learning. Flooding attacks, spoofing attacks, and ping flood, leave behind them a different type of traces and then lead to various statistical features. For example, a ping-flood attack is a DDoS attack in which the attacker attempts to flood a targeted device with ICMP echo-request packets, causing the target to become inaccessible to usual traffic. The Internet Control Message Protocol (ICMP), which is utilised in a Ping Flood attack, is an internet layer protocol used by network devices to communicate.
For our little toy-implementation, we will use KDD intrusion dataset detection. The KDD training dataset consisting of 10% of the original dataset contains approximately 494,020 single connection vectors and 41 features. Each vector is labeled as either normal or an attack, with exactly one specific attack type. Deviations from ‘normal behaviour,’ everything that is not ‘normal,’ are considered attacks. Here are the possible values of ICMP-related attacks :

Note that we will use only two labels, thus won’t classify exactly the type of attack it is but only try to detect any unusual network activity. We want this little implementation to be as simple as possible, so we will use Decision trees to perform classification, but what makes DDoS detection difficult for machine learning classifiers?
- Our dataset is exceptionally imbalanced, as we have more than 169.000 lines and 378 labeled attacks.
- Detect and mitigate DDoS attack has to be performed quickly.
- Raising a significant amount of false-positive and classifying any unusual activity as a DDoS probably improves security, but inhibits efficiency.
Using a toy Decision-tree classifier, with a depth of only 3, we only miss 6 DDoS attacks on our test sample, which is sufficient to lead to epic lossage and obtain the following feature importance histogram :
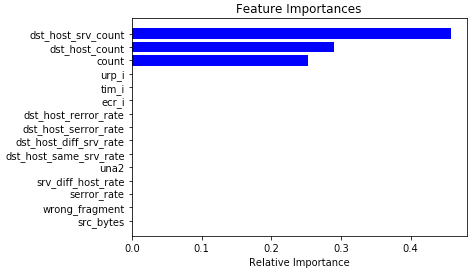
In fact, features declared as important in terms of information criterion makes a lot of sense, but could usually lead to a very biased system only able to detect the most naive DDoS attacks. A sophisticated low-bandwidth scheme or malicious usage of mobile botnets would not be efficiently mitigated. Indeed, mobile phones continuously change their connection to networks, and the combination of rate-limiting and blacklisting would no longer be sufficient.
The notebook is available here.