Hacking GraphQL for Fun and Profit (1) - Understanding GraphQL Basics


Hello everyone, In this Part One of my series on hacking GraphQL I will be going through some basics of GraphQL to understand the technology better, and in Part Two I will hack a demo application.
There are tons of good resources available, the official documentation is top notch. This blog is just an overview of the technology and how to use available resources for best results.

According to the official documentation,
GraphQL is a query language for your API, and a server-side runtime for executing queries using a type system you define for your data. GraphQL isn’t tied to any specific database or storage engine and is instead backed by your existing code and data.
In simple terminology, GraphQL is a data querying and manipulation language that performs the same functions as REST. Similar to RESTful HTTP methods, using GraphQL we can do CRUD operations in the API with much better precision.
Why GraphQL?

GraphQL solves following 2 major problems of REST API implementation.
- Unnecessary data fetching leads to utilizing high bandwidth (Over fetching)
- Unnecessary implementation of different endpoints for different functions leads to complexity and need to do multiple calls from front end to get required data. (Under fetching)
Above mentioned both the problems solved by GraphQL as you can query same URL endpoint in order to perform different actions and you can also query only required data you want which eventually saves computational time and memory.
How does GraphQL work?
As mentioned previously there is only 1 endpoint to request but at same time you must be sure what information you require as GraphQL will only return information which was asked.
GraphQL contains following operation types:
Queries
It is used to fetch data using specifically defined query operations. Similar to a GET request in API. You can request any field easily including the data associated with that fields.
Query is what you actually asks the server what you want and server will respond with the same data you have asked for. Queries can have arguments and based on those arguments specific data can be queried.
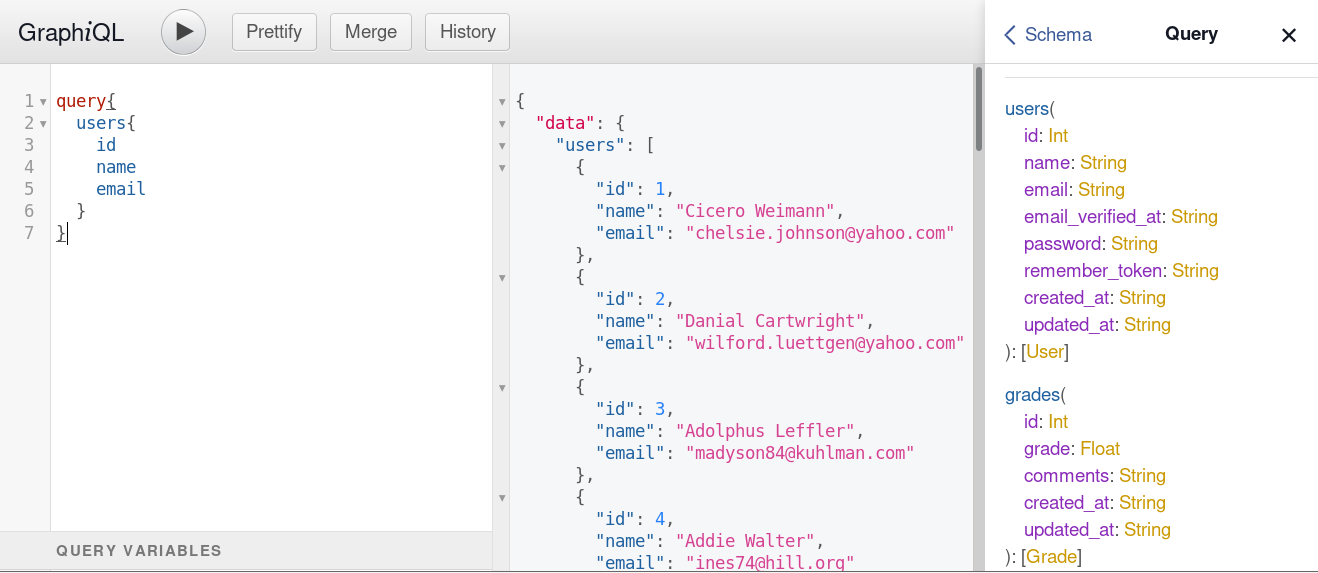
As we can see in above snapshot, on the right there is definition of data we can ask and on the left we have asked the data we want.
Mutations
If queries are used to fetch data, Mutations are used to perform Insert, Update, Delete the data in system. It is similar to DELETE, PUT, POST requests. On advantage of doing this in GraphQL is we can ask updated content in same request so no need to query it differently.(Remember the problems of REST API?)

As you can see in above snapshot, there is mutation called userMutation and we have provided password which eventually changed password of the user containing id ‘1’.
Resolver functions
A resolver is a function that’s responsible for populating the data for a single field in your schema. It can populate that data in any way you define, such as by fetching data from a back-end database or a third-party API.
Some others components which we aren’t going to discuss in this blog like subscriptions, fragments and directives.
Where to find?
Let’s come to actual point, where we can find GraphQL and how we can identify that the application is using GraphQL implementation. There are multiple ways we can identify that application is using GraphQL. Some of them are:
- Specific endpoints: Sometimes GraphQL endpoints have IDE interface enabled like following:

2. Fuzzing for endpoint: One can fuzz for endpoints using following common endpoint list.
 danielmiessler
danielmiessler
Introspection
Introspection is the ability to query which resources are available in the current API schema. Given the API, via introspection, we can see the queries, types, fields, and directives it supports.
Having a publicly available introspection query is not a bug. It’s a FEATURE. If it’s a production environment disabling it will be considered as best practices. But sometimes it will disclose some sensitive details which can be considered as a bug. Introspection query gives complete documentation and list of what API calls are available in the back-end and a good overview of the structure of the system.
Examples:
- Single line query to dump the database schema without fragments.
__schema{queryType{name},mutationType{name},types{kind,name,description,fields(includeDeprecated:true){name,description,args{name,description,type{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name}}}}}}}},defaultValue},type{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name}}}}}}}},isDeprecated,deprecationReason},inputFields{name,description,type{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name}}}}}}}},defaultValue},interfaces{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name}}}}}}}},enumValues(includeDeprecated:true){name,description,isDeprecated,deprecationReason,},possibleTypes{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name}}}}}}}}},directives{name,description,locations,args{name,description,type{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name,ofType{kind,name}}}}}}}},defaultValue}}}
2. URL encoded query to dump the database schema.
fragment+FullType+on+__Type+{++kind++name++description++fields(includeDeprecated%3a+true)+{++++name++++description++++args+{++++++...InputValue++++}++++type+{++++++...TypeRef++++}++++isDeprecated++++deprecationReason++}++inputFields+{++++...InputValue++}++interfaces+{++++...TypeRef++}++enumValues(includeDeprecated%3a+true)+{++++name++++description++++isDeprecated++++deprecationReason++}++possibleTypes+{++++...TypeRef++}}fragment+InputValue+on+__InputValue+{++name++description++type+{++++...TypeRef++}++defaultValue}fragment+TypeRef+on+__Type+{++kind++name++ofType+{++++kind++++name++++ofType+{++++++kind++++++name++++++ofType+{++++++++kind++++++++name++++++++ofType+{++++++++++kind++++++++++name++++++++++ofType+{++++++++++++kind++++++++++++name++++++++++++ofType+{++++++++++++++kind++++++++++++++name++++++++++++++ofType+{++++++++++++++++kind++++++++++++++++name++++++++++++++}++++++++++++}++++++++++}++++++++}++++++}++++}++}}query+IntrospectionQuery+{++__schema+{++++queryType+{++++++name++++}++++mutationType+{++++++name++++}++++types+{++++++...FullType++++}++++directives+{++++++name++++++description++++++locations++++++args+{++++++++...InputValue++++++}++++}++}}
Now when you do this The response might be quite big. The best way to understand the schema is to visualize it. Following are the steps to do that.
- Copy the entire response body
- Go to GraphQL Voyager

3. Click on the Change schema button and go in the introspection tab.

4. Paste the introspection query.

5. Click on display and you will see visualization of entire back-end.

Using this method now we can identify the sensitive API calls and abuse them (in ethical way obviously).
We will be working with a demo application to understand all this in our next blog. Hope you learn something new and enjoyed my blog. Stay safe, stay curious.
Thanks for reading!
~Nishith K
Twitter: https://twitter.com/busk3r
LinkedIn: https://in.linkedin.com/in/nishithkhadadiya
References
- https://graphql.org/learn/
- https://medium.com/swlh/using-restful-apis-versus-graphql-1e6c350d56c9
- https://payatu.com/blog/manmeet/graphql-exploitation-part-1
- https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/GraphQL%20Injection
- https://the-bilal-rizwan.medium.com/graphql-common-vulnerabilities-how-to-exploit-them-464f9fdce696
- https://blog.yeswehack.com/yeswerhackers/how-exploit-graphql-endpoint-bug-bounty/
