The Stoic Approach To OSINT
The deep thinkers approach to OSINT. What if all you had was a search engine? A complete and total focus on observable evidence linked by inferences.


This article is a primer on some of the techniques and methodologies I use to conduct dedicated OSINT engagements on some of Australia's biggest organisations, top CEO's, celebrities, alleged hackers and disgruntled employees. All of these OSINT techniques can be applied to other purposes, they are incredibly useful in missing person searches, in support of red teams during penetration tests, or by privacy-seeking individuals conscious of their digital-footprint.
Open-Source Intelligence (OSINT) is a very wide, deep area of digital investigation that often requires more analysis than it does tools. The goal of this article is to show you how to conduct deep and thorough OSINT engagements on organizations, infrastructure and individuals using nothing but a browser. Tools are out, in the next steps we will cover process, technique and methodology.
The information we are looking for might not be direct or even indirectly linked to our subject and we want to look for information that fits into the following categories: Direct, Indirect, Inferred, Analyzed and Cross-Referenced (DIIACR).
TL;DR - this article is split up into components. Feel free to breeze past what you know, and look for the topic heads. Specific techniques are labelled with "$$$".
What this is:
Manual, focused, insanely simply humanoid process.
Minimal requirements (e.g. could undertake with your mobile phone).
What this is not:
Conducting mass-OSINT on multiple targets at once
Point-and-shoot scripts or tooling such as Recon_NG, theHarvester, Maltego
Stoicism
The stoics of ancient Greco-Roman times were deep thinkers, the name comes from 'stoa poikilê' which was the building in Athens were members congregated to hold lectures and conversations. They lived by some very simple 'rules' that I have listed below and which are directly translatable into OSINT:
- What happens when you go 'vanilla' and strip away all the tools.
- Complete and total focus on observable evidence linked by inferences.
- Linking rational connections with logical thoughts for insane accuracy.
- Follow the 'olive-tree-branch' method of thinking.
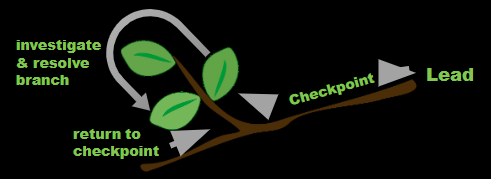
Preferred Outcomes
The aim of conducting OSINT is to influence positive change. Either the infrastructure is hardened and protected, the organization's profile is fine-tuned to reveal less, or you mitigate potential malicious opportunities for attackers.
Discover what digital assets an organisation has before scoping individual subjects.
e.g. ACME scopes a pentest on a hardened website before implementing awareness and protections against spear-phishing attacks on their CEO.
Identify and mitigate possible scenarios of blackmail, extortion and fraud.
These opportunities for attackers don't have to be sex scandals and fraud. They can be assets, hobbies, affinities, habits or family related.
Assess the organisations threat surface in relation to their digital footprint.
Is there a forum dedicated to hacking a specific product of theirs? Discussion around perimeter security holes? Acquisition and merger leakages?
Tighten the reigns on the organisation (and their staff) social media disclosures.
Do people reveal photos of internal physical sites? Does their twitter announce when everyone will be away on a training seminar?
Dedicated OSINT Engagements
We conduct OSINT all the time during pentests, digital forensics and incident response (DFIR), the problem is that OSINT is usually treated like a sub-activity rather than a dedicated engagement. Leveraging the rules I outlined above can make your OSINT strong, but stretching these into a full-fledged engagement can provide some epic outcomes.
To highlight this point and through this article we will look at three core targets, they all end up hand-in-hand.

The head of the snake. What can we find with OSINT that could lead to malicious opportunities for blackmail, extortion or fraudulent evidence?

Chatter and sentiment. What forums, articles, reviews or online comments could lead or link to potential security controls, issues and measures?

High-confidence attack vectors. Can we find database breaches, compromised accounts or passwords that could lead to spear-phishing?
We can then chain some of the discoveries we make together to:
- Feed this information into a Red Team.
- Fine-tune anti-phishing and social-engineering detection tools.
- Educate and prepare for worst-case scenarios and enrich our threat intel.
Our sources are simple. Remember, everything that is observable online, free (no paying XMR for breached accounts!) and accessible on a mobile device. Most here are interchangeable between the three.
Select Individuals
Social Media, Search Engines and Indexes, Portals, Platforms and Archives
Organisation Profile
Social Media, Search Engines and Indexes, Clearnet and Dark Web sites
IT Infrastructure
SSL Certificate Authorities, Subdomain Enum Tools, Archive and Repository sites
Google Dorks Primer
Google Dorks are old, and 99% of readers will already know what they are. They've been around for a long time, but are still extremely useful. Let's touch on them again:
Functions
To target results that appeared only at a certain time, we will use the Date function. A more advanced version is the daterange: dork (https://www.oreilly.com/library/view/google-hacks/0596004478/ch01s17.html) but for now let's just use: Google -> Tools -> Time (D, W, M, Y, Custom).
Example: A company went through an acquisition in 2009. We want to find any rumours that leaked onto the web just before the press release. We don't want results for the RANDO acquisition either. We'd use something like: Date: Sept-2008 - Sept-2009. site:reddit.com intext:"ACME acquisition" -RANDO
Dorks
Now onto the dorks. Different keywords will produce different results:
“NASA"
Will display all search results that include the string NASA (e.g. without the parenthesis, this will also display results for NASAL PRODUCTS).
–space “NASA”
Will display all search results that match ‘NASA’ and do not include the word ‘space’.
-nasa.gov “NASA”
Will only display matches for ‘NASA’ that do not appear on nasa.gov.
site:nasa.gov “secret”
Will only display matches for ‘secret’ that only appear on nasa.gov.
filetype:pdf “pineapple”
Will only display indexed PDF files that contain the word “pineapple”
inurl:nasa
Will only display results with the string “nasa” in their URL (e.g. wired.com/nasa-is-actually-aliens)
Let's get started...
So now that we have those results we can start thinking about the different sources and information we gained from search engines relating to the different word clouds we will form. There are way too many techniques to cover in this, but we're going to introduce and focus on just one or two key concepts:
Organizational Profile Review
Let's just touch on this, we'll come back to it.
Targets
- Security, safety and threat-related information
- Online sentiment, news, chatter and reviews
Example Findings
- Blueprints or building plans for physical sites
- Forum or social media sites referencing comment or conversation threats
- General online sentiment and past/present employee comments
- Lobbyist groups, political and business discussion
Selected Individuals Review
Alright, let's focus on this part, and introduce some details.
Targets
- Critical information that may be disclosed if blackmailed or extorted.
- Domain network or compromised accounts via spear-phishing.
- Personal Identifiable Information (PII) for staff in key positions.
Example Findings
- Information shared online that could lead to password-guessing attacks.
- Social media interactions leading to spear-phishing opportunities.
- Information, comments and relationships with the potential for journalistic-investigations and/or newsworthy articles.
Search Categories
Some areas that we would like to cover here includes the following categories, which combines precursor, targeted, technical vector, and golden ticket information:
- Aliases, usernames, full and previous names.
- Groups, memberships, affiliations, clubs & organisations.
- Personal Contact Information (phone, email).
- Education Information (Schools, universities).
- Travel Information (Transport, Vehicles).
- Public Persona (Conferences, talks, meetups, workshops, interviews).
- Location Information (Residence, properties, popular visitations).
- Personal Information (DOB, secret Qs, family members, pets, relationships).
- Personality Information (Hobbies, traits, weaknesses, favorites).
- Business & Legal Information (ABN, holdings, shares, court orders).
- Digital Presence (Social Media, Search Engines, revealing Images, forums).
- Technical Information (Device types, PINs, leaked/passwords, tech).
- Sensitive - NSFW things (Rships, dating, cheating), Financial, Assets.
Word Clouds & Transformations - $$$
There are many naming conventions. This is because people were addressed differently in the old days, different countries use other terminologies, or entities use initials and short names. We should be prepared to transform a target's name into at least multiple potential search vectors. These can be paired with all our other findings, from different olive-tree-branch searches.
Let's use the name 'Larry Noble' as an example. Try and identify how many examples wouldn't have popped up if we used simple name conventions. Examples are below.
Formalities
Mr Noble, Dr Noble, Ps Noble, Sr Noble
National News Site
"Mr. L.N from Melbourne won the OzLotto Powerball of $5.3 million AUD on Tuesday."
Initials and old language
M Noble, Mr LG Noble, L.G.N, Noble Jr
HockingStuart Facebook Page
"We successfully sold L & J Noble's beautiful Templestowe property entirely in bitcoin! Congrats to the happy couple!
Known as by Friends, Nicknames
Larry, Lars, Laz, 'Nobs' or even just 'Noble'
Reddit /r/vegan
"Yeah my boy Larry N was totally a part of that vegan protesters group at the Downtown steakhouse!!" ~ Jd33_67
Social Chaining - $$$
Social Chaining is a technique I use to obtain information that is on the public domain, but hidden or guarded from 'direct queries'. For example, private social media accounts and protection mechanisms would prevent your searches from landing on the target. However, using links from adjacent family members and 3rd parties, we can eventually obtain that information.
Let's say we want to find the street address of our target, James Yurt. Searches of James Yurt and his wife Stephanie Yurt come up with nothing on google. Being a common name, the time taken to go through all links would also take too long. Let's follow the process:
- Search for the surname 'Yurt' on facebook. A woman 'Merideth Yurt' appears, and while nothing points to her being family, her friends list allows searching.
- We search for 'Yurt' and this time Stephanie Yurt appears, her profile completely private, and search engine visibility turned off.
- We notice that Stephanie's facebook profile URL is facebook.com/stephbarnes.
- We infer that 'Barnes' is Stephanie's maiden (pre-marital) name. Let's search this in google: "Stephanie Barnes". An Australian Business Number (ABN) references her at-home arts and crafts business she ran under her maiden name.
- The ABN also includes middle name, and suburb that she registered the business under - 3337 'Melton'.
- Using this information, we construct a new query using the location lead, returning to the initial olive branch where we focused on Jame's partner.
intext:"James Yurt Melton"
intext:"J Yurt Melton"
intext:"Mr J Y Melton"
intext:"James Y Melton"
intext:"Yurt Melton"
7. Bingo: We get a reference for a real-estate company advertising the purchase of a new house in 2016 for newly married Mr. and Mrs. Yurt, in Melton, with the street address in the background of the photo.
What we have done here is go from point A to B, by using social chaining techniques, gathering a full word cloud about our target and used naming convention transformations to fine-tune the process. Along the way, we've also added some new leads to our olive tree, such as family member (Merideth), partner's business, street address, suburb and so forth. These would be collected and investigated individually.
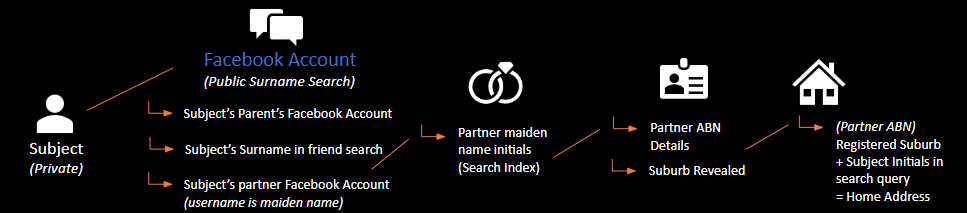
IT Infrastructure Review
Now let's see what we can find from outside an organisation that could allow us to see inside, or get a feel for the internal IT landscape.
Targets
- Internal IT Networking, server and system information
- Foothold or privilege escalation login portals
- Breached or compromised corporate accounts
- Public and private facing infrastructure asset discovery
Example Findings
- Development, staging or newly-added sub-domains
- Old, deregistered, internal or not-in-use subdomains
- Internal share, drive and server names (e.g. \\TEST, G:)
- Directory structure and file paths (e.g. X:\Technical Data\Contractors\)
- Organisation and employee default, compromised or breached accounts and credentials
Data Transformations - $$$
Many documents are created and produced within a company that end up on the internet. We can use this by creating a word cloud out of any kind of document, and using those as iterative search queries, expanding our search net.
Let's see how we can create goals to transform known, standard information into discovering unknown, sensitive information. We can do this by following:
Target entity -> Document/Digital Asset -> Word Cloud -> Analysis/Olive Branch -> New results -> Word Cloud -> Further Analysis = Bespoke Info
Each ‘word cloud’ might come from a discovered piece of information, file, document, blog, photo, friend etc. The analysis part substitutes them back into your Google Dorks which results in further items, and so forth.
Let's use an example. We conduct a simple search for documents online for an organisation called 'CloudA2'. Our search query could be something like:
CloudA2 “sensitive” filetype:pdf
This will search for any PDF files cached within Google that reference CloudA2 and must contain the term 'sensitive.
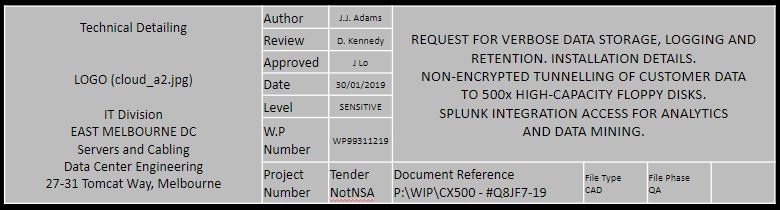
The resulting document (above) appears; there are a number of things we can do here. First off, we notice that the filename has incorrectly been saved with the company internal URL. This not only provides us with potential folders and names to use in further queries, but online files as well.
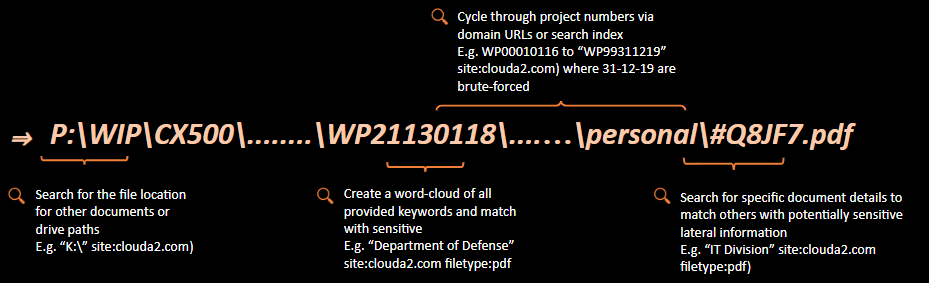
- Iterating from A to Z, just like an Insecure Direct Object Reference (IDOR) vulnerability, we could assess the company for other files or potential drives (especially if documents online contain references to those).
intext:clouda2 "A:\" filetype:xlsx
2. Instead of just 'sensitive', we could attempt to find their classification terminology. When we find their legend, we can orient our search to only target more sensitive documents. This could include confidential, privilaged, private, personal, classified, confidential, for official use only, commercial in confidence....etc etc you get the idea. My personal classification list has over 40 terms in it, happy to share that where required - it's basically just synonyms though.
For example, if we wanted to see if any networking plans accidentally included references to military sites and were leaked on line (serious reputational and national risk to the org), we could iterate through relevant terms of the following:
intext:clouda2 "Department of Defense" filetype:docx
3. Getting a bit more focused here, we could do a complete document dump by again bruteforcing project numbers. Where WP99311219 exists, we assume it means Working Project (##) DD MM YY. Let's go from WP00010112 all the way to WP99121219 (yes, scripted automation is a good use here) or to look more recently, just iterate the project, DD and MM for this year.
site:clouda2.com.au intext:"WP33240219" filetype:pdf
4. Moving along, we might find that different divisions in the organisation also produce different document types (e.g. .doc, .dwg, .dxf, .shp, .pub) and standards, with their own classification schemes (and potentially more juicy leaked docs). Keep in mind - this can happen for a number of reasons - incorrect saving and hosting of files, incorrect recursive directory/file permissions, random/old/forgotten file servers, cloud storage - the list goes on.
site:clouda2.com.au intext"HR Division" filetype:pdf
Non-indexable Information Gathering - $$$
Sometimes information is in the open-source landscape, but protected by various levels of trust and privilege. There are 'portals' which can be abused.
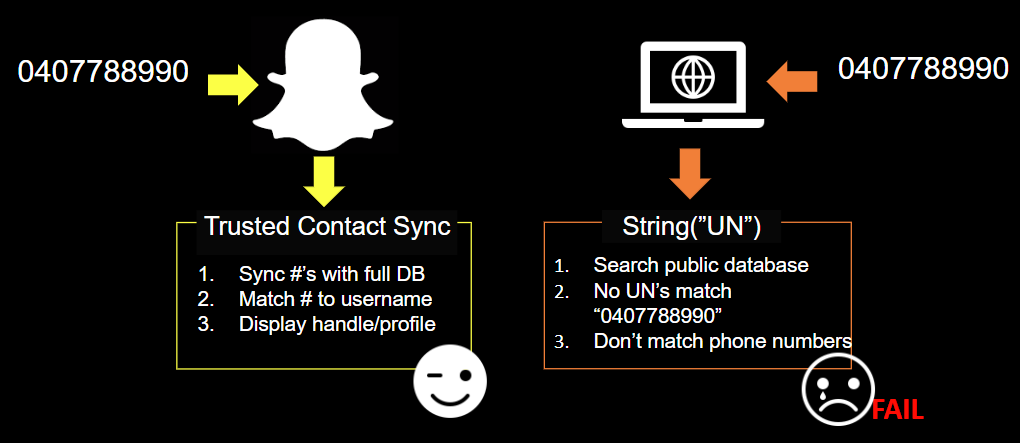
Let's start - you have a target's phone number: 0407788990
- Most likely, that phone number was used to set up multiple accounts and registrations.
- Index and social media searches return with no results.
Trusted, third-party applications can make requests on behalf of us where user-input would fail (similar to SQL injection making queries to a database on behalf of the web application's privileges). Let's look at a case study:
Snapchat - abusing one-way contacts to enumerate hidden accounts
Long story short - snapchat won't allow you to search for people in the app by their phone number. However, we can find their accounts if we use Snapchat's 'sync' function instead, by placing the phone number on our device as if it were a trusted 'contact'. To explain things a little easier, I've colorised it a little...

Attack Scenarios
We've covered a few techniques for deep, targeted searching. We do this because engagements for businesses allow from a couple days to a couple weeks, when the more nefarious-minded individuals have weeks, months and even years.
What do they see when conducting similar searches? Let's go through a few examples.
OBSERVATION (A)
Our searches lead us to find the target's initials appear in multiple public prize-winner pages suggest the subject is an avid fan of lotto’s and competitions.
- All competitions were held through OPTUS Mobile and displayed on their site
- Many competition wins, with prizes randing from data additions to gift cards
- Win history stretches from 2012 - 2018, demonstrating a long-term loyalty.
ATTACK METHOD (A)
Target the user with a spear-phishing attack mimicking that of the identified mobile provider. The email would reference previous wins, thanking them for their continued participation and request additional information to upgrade their plan free of charge with extra data. The added PDF could also contain a malicious payload.
Remember; this might be a very small chink in the armour, but if our end-to-end goal was to compromise the organisation, we have a solid pre-text, a targeted individual, and high-confidence that the subject will be spear-phished and a potential entry into the company network. Once there, if we already know what kind of internal drives, servers and file-shares they have, we can reduce our network presence by accessing what we already know - staying under the radar (fewer network requests for invalid objects) and spending less time figuring out the lay of the land.
OBSERVATION (B)
Public posts on a business social media page identify the subject’s negative experience and emotional discussion.
- News outlets also indicate no resolution to the situation (experienced by many)
- The subject is less likely to use logic (emotional appeal) when assessing validity of phishing email, as they are jaded from the experience and want a resolution.
ATTACK METHOD (B)
Target the user with a spear-phishing attack mimicking that of the identified business. The email would reference the unfortunate situation, providing a positive alternative to amend the negative associations with the company. The alternative would likely request further details or deliver a malicious payload in the form of an attachment.
OBSERVATION (C)
In our search for company reviews and staff comments, we identify a post by a security contractor/guard.
intext:”security officer” cloudA2 review
The review mentions a few things, but touches on the following specific points:
- Drunks making their way into the CloudA2 Richmond site at night
- Job can be boring, answering calls, managing concierge desk, doing the rounds
ATTACK METHOD (C)
This review is interesting as it suggests a number of the following items:
- Multiple roles (e.g. calls, desk, rounds) may indicate security role is hybrid - might indicate the guard is not properly trained or 100% focused on observing potential threats and high-risk individuals
- Provides some details of a site that can be physically compromised
- Provides a great pre-text for a Red-Team scenario (e.g. "Hey Ryan, heard about those drunks in Richmond! They've actually sent me out to investigate ways we can prevent that; i'm collecting details on it all - where did you say they were getting in again?")
Conclusion
There are many ways to collect and conduct OSINT. I hope this small primer has given you a few ideas around thorough collection and investigation of leads, and the creation of sub-leads through inferences, word clouds, non-indexable information and data transformations.
- OSINT provides a passive, non-intrusive pathway for demonstrating devastating attack vectors without even touching the organisation's systems.
- These results can provide pentesters and red teamers with multiple pathways of attack, backup and additional pre-texts.
- Comprehensive (10 day plus) dedicated OSINT engagements can result in a stupidly high level of confidence and success rates in targeted, chained attacks.
- The devil is in the remediation. Seek organisational and behavioural change in how you make recommendations. You don't want an internet scrub, you want a change in psyche for future actions and accountability moving forward.
Some Links I like
Stoicism
https://www.youtube.com/watch?v=R9OCA6UFE-0
Bellingcat
https://www.bellingcat.com/
Hunchly
https://www.hunch.ly/
Automating OSINT with python
https://register.automatingosint.com/
