Research Scanned Documents with Optical Character Recognition


Optical Character Recognition (OCR) means that your computer can read words in photos and scanned documents. When you have a document or documents where you want to copy and paste the words into a search engine or you want to do a word search for a specific name in the document, OCR will make that possible.

For example, two previous posts described how you can research the tax records of nonprofits’ tax records or politicians’ financial disclosures, in government databases but the records are all in badly scanned pdf documents that do not recognize the words. Therefore if you want to find if Exxon Mobil’s foundation donated to a Senator’s personal nonprofit, you have to potential search through a lot of pages of tax records to look for the name.
This article will explain how to use Python to add OCR to files.
Get Started on Installations
You will need Python, Sublime Text, and Pip for the basics.
To start with, if you are completely new you can download Python from https://www.python.org/downloads/. Then you can download Sublime Text, a tool for accessing Python scripts, at https://www.sublimetext.com/3.
Now, access your Command Line (if you are using Microsoft) or Terminal (if you are using Mac).
Pip is included in Python but you can see guidance for installation and updating at https://pip.pypa.io/en/stable/installing/.
If you get a message saying you need to upgrade pip, you can do so in the Command Line by typing: python3 -m pip install –upgrade pip
The next group of installations are Pillow, Tesseract, and Pytesseract
Next install Pillow by going here for instructions.
(Install Pillow on Windows by typing: python3 -m pip install –upgrade Pillow)0
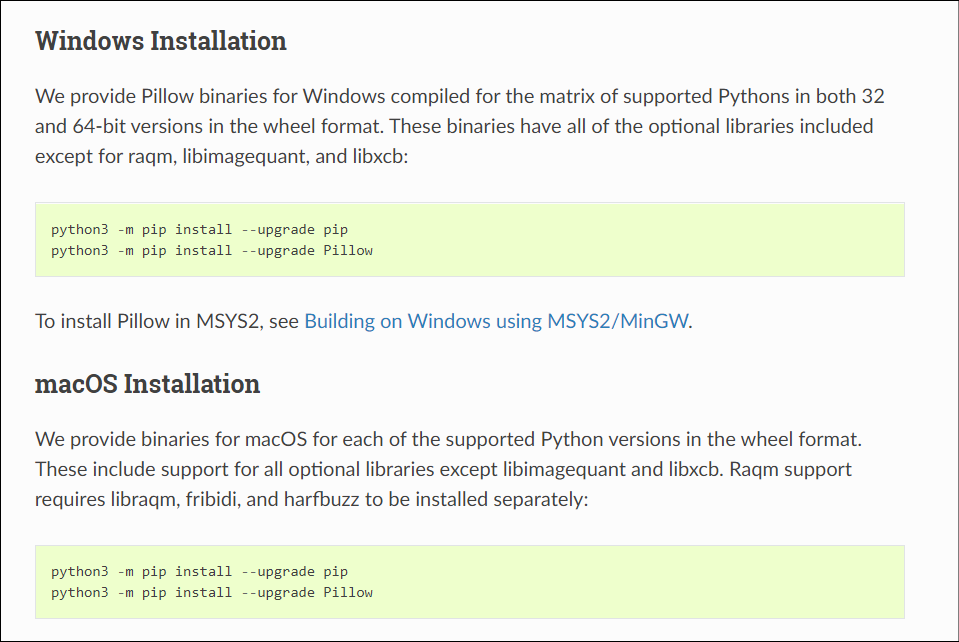
from – https://pillow.readthedocs.io/en/stable/installation.html
Tesseract
There is the command-line program Tesseract and its third party Python “wrapper” (whatever that means) named Pytesseract.
Click here for a basic overview of Tesseract and its installation and usage, see screenshot below. Following the below screenshot there is a link to the more detailed documentation on installation.
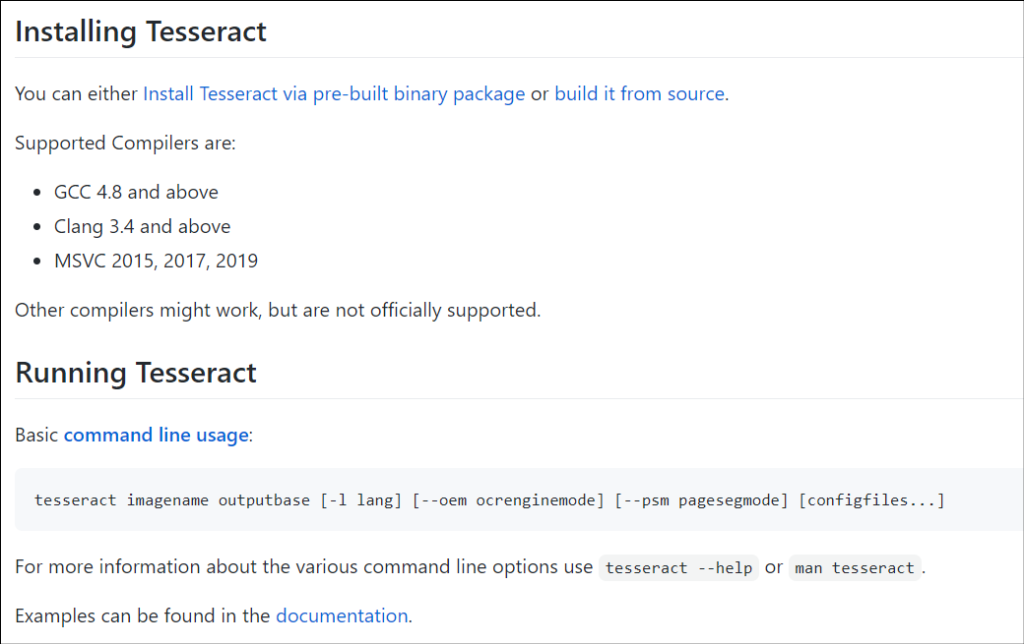
Go here for installation documentation.

Note in the window below in the second para that, for Windows, if you want to OCR different languages you need to click on the link that says “download the appropriate training data”, which brings you to a webpage that offers a different download for each language.
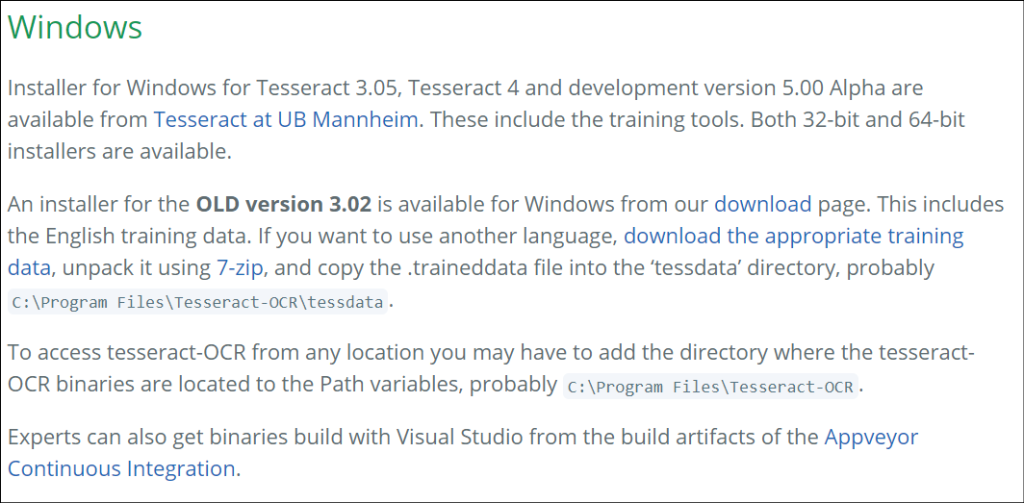
Tesseract installers for Windows are available here.
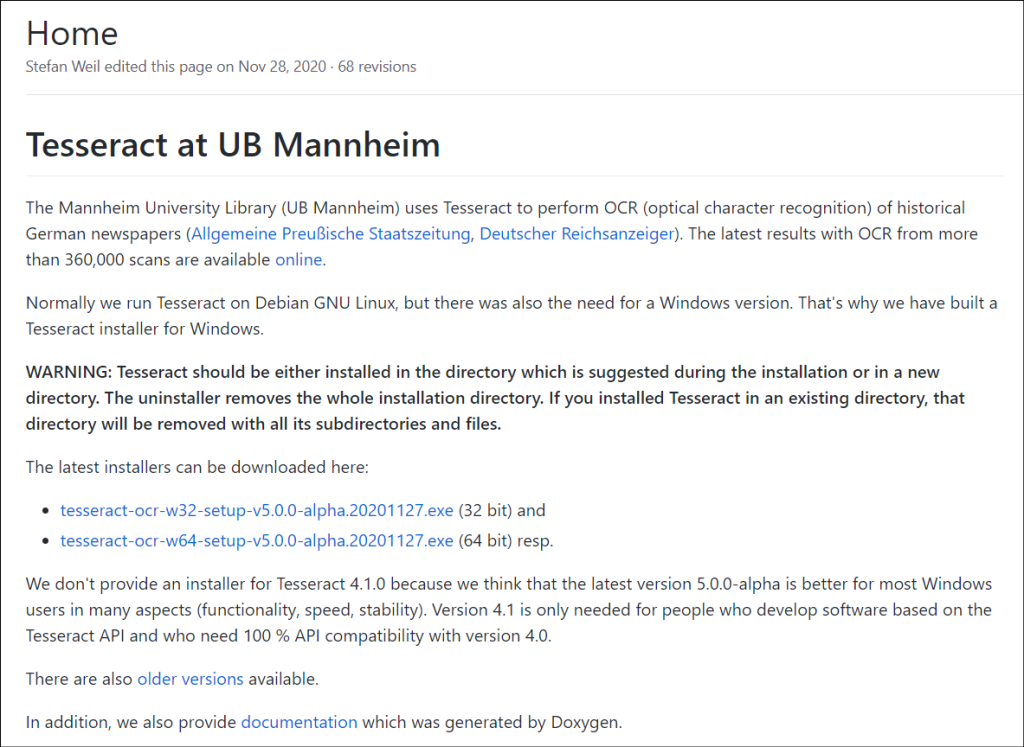
The process for Windows should identify the location where it is downloaded, this is necessary to know so that “you can put it in your PATH” (a phrase that is often used by rarely explained with Python).
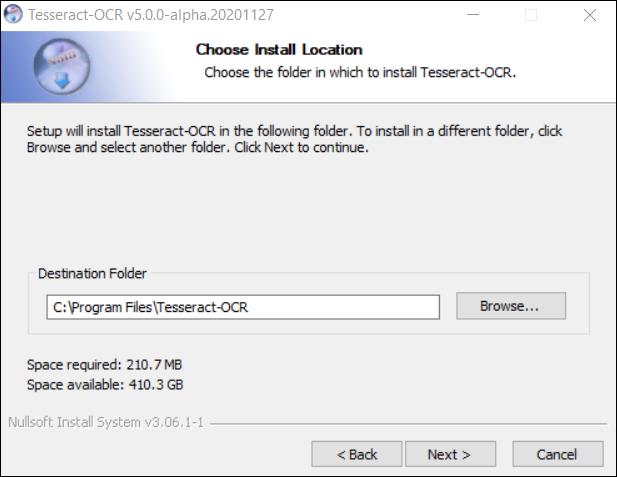
You have installed tesseract and if you are using windows it will default to the location above.
How to Add Something to the PATH
Next, tesseract must be “added to the PATH”, this means that you must add the directory of tesseract must be added to the PATH environment variable.
The following instructions are for Windows.
1- go to System Properties
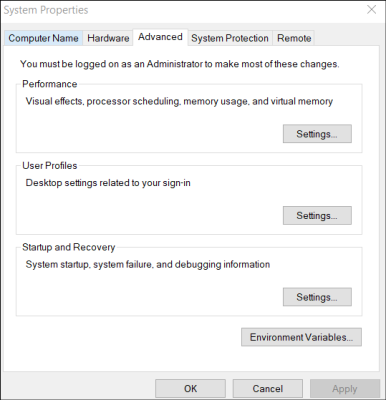
2- click on Environment Variables
3 – a box will appear that it titled Environment Variables, within it find where it says System Variables and underneath that there is a list of variables, choose the one titled PATH
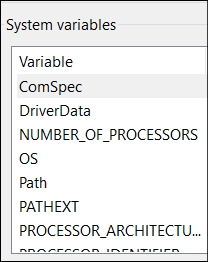
4 – a new window appears, click on one of the empty lines then click on browse and find tesseract, click on the tesseract folder (or “directory”) then click on okay until you have closed every box
Now when you open the command prompt you should be able to hit the command from any folder and be able to access tesseract.
Pytesseract
To install the python wrapper library, Pytesseract, which uses existing Tesseract installation to read image files and out put strings and objects that can be used in Python scripts.
You can run “pip install pytesseract”, or go here and download the file and then run “python setup.py install”
Command Line / Terminal command for OCR
The python capabilities described here require that you have a png file, not a pdf. Most pdf conversion capabilities are not friendly to Windows. But the methods here will work just as well for Mac.
How to get a png file? Most snipping and screenshot tools will automatically create a png file of the image you are capturing. If you are working with a pdf file and only need one page, you can snip an image of that page.
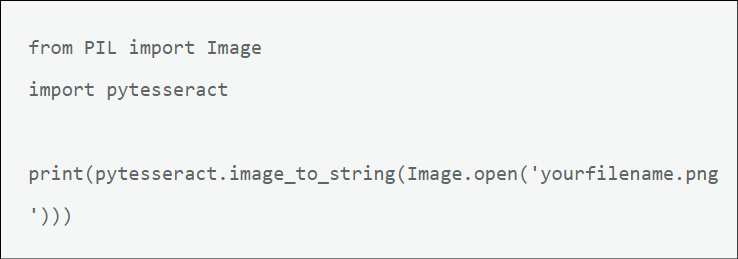
Here is a very basic OCR python script. The script must be saved to the same folder/directory as the png file that you want to read. If not, then you would put the path instead of just the name. So if the python script was saved to a folder named “first” but the png file was in a folder named “second” that was located in that same folder named first, then instead of (‘yourfilename.png’), you would type (‘second/yourfilename.png’). This is otherwise known as the path to your file.
There are many python interpreters but for this post we suggested using Sublime Text. To run a script in Sublime Text you must save it (File, Save or Ctrl-S) then take the not intuitive step of chooseing to “build” (Tools, Build or Ctrl-B).
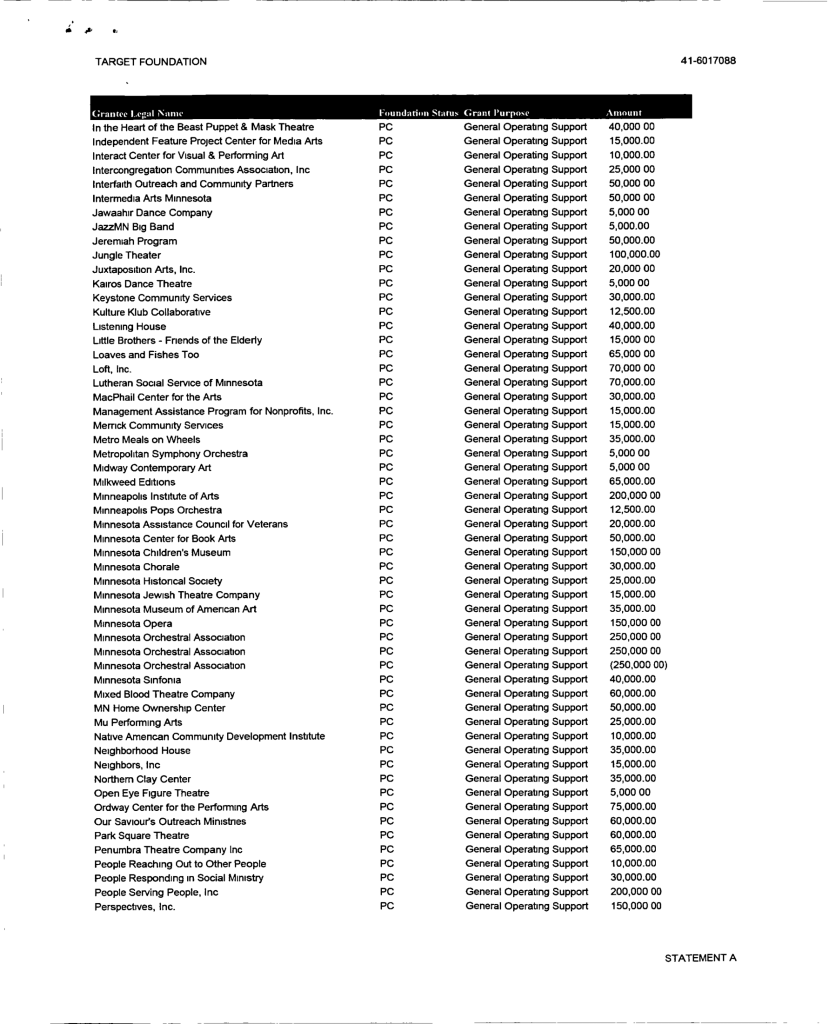
For this example I used a png file of a list of donation recipients from the Target Foundation’s tax records that looks like this

The aforementioned python script will produce a list of words and phrases printed out into the python interpreter and should look like this:
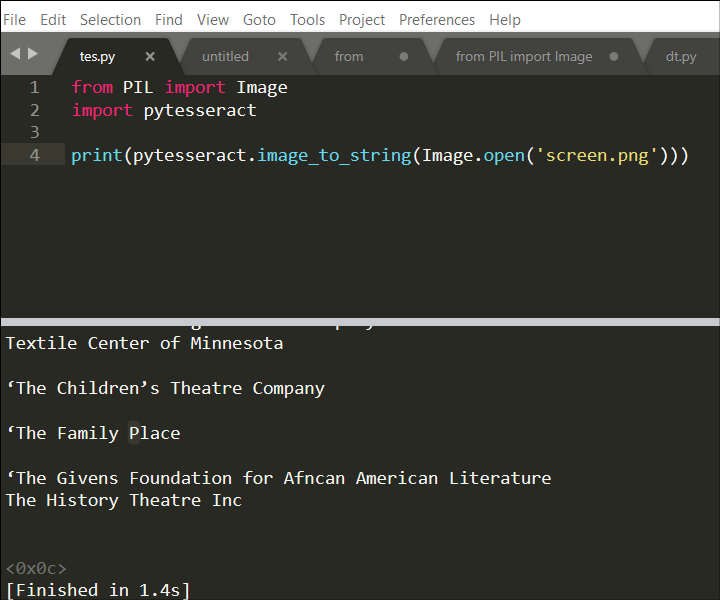
If you want to print out that same list into a txt file, you could go to the Command Line / Terminal, navigate to the folder with the python script, and then type “tesseract”, space, the png file name, space, then the name you want to give the text file with your list, like so: tesseract yourfile.png textfile.txt
The following script will take your original png file and convert it into a pdf file that has OCR over the words
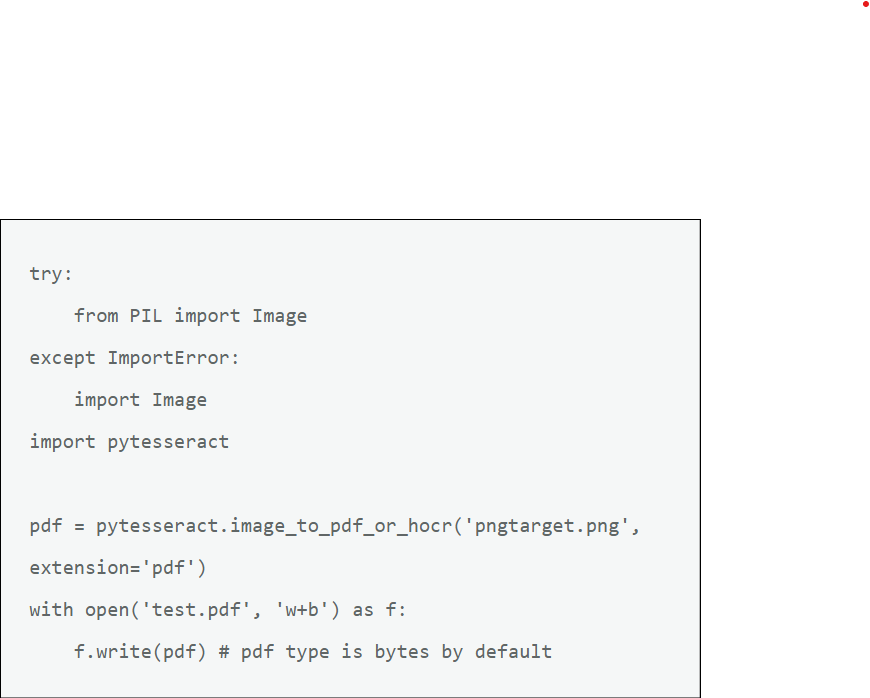
try: from PIL import Image except ImportError: import Image import pytesseract pdf = pytesseract.image_to_pdf_or_hocr('pngtarget.png', extension='pdf') with open('test.pdf', 'w+b') as f: f.write(pdf) # pdf type is bytes by default
The resulting pdf looks like this (with words highlighted):

This method was equally successful when used on the full page of the original document that looked like this:
How to create and print list to a TXT file
According to a instructions from w3schools.com, if we want to create a new text file:
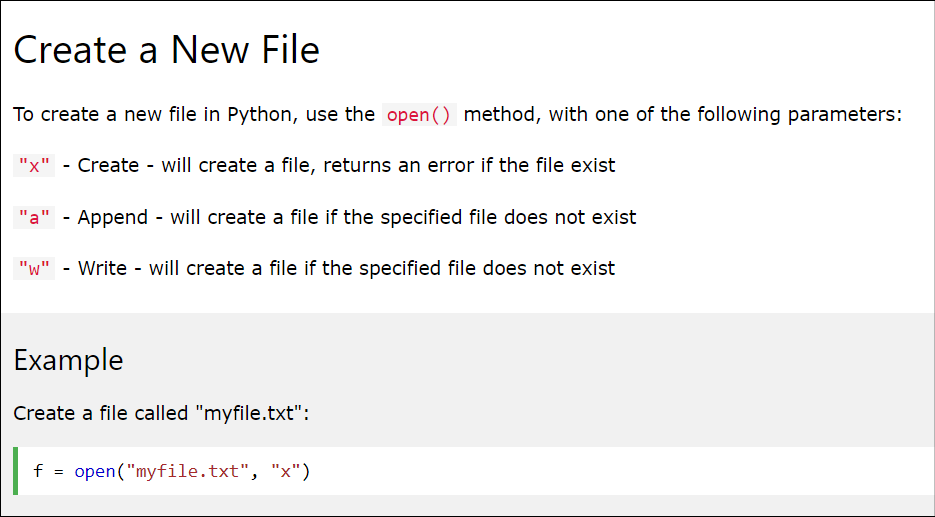
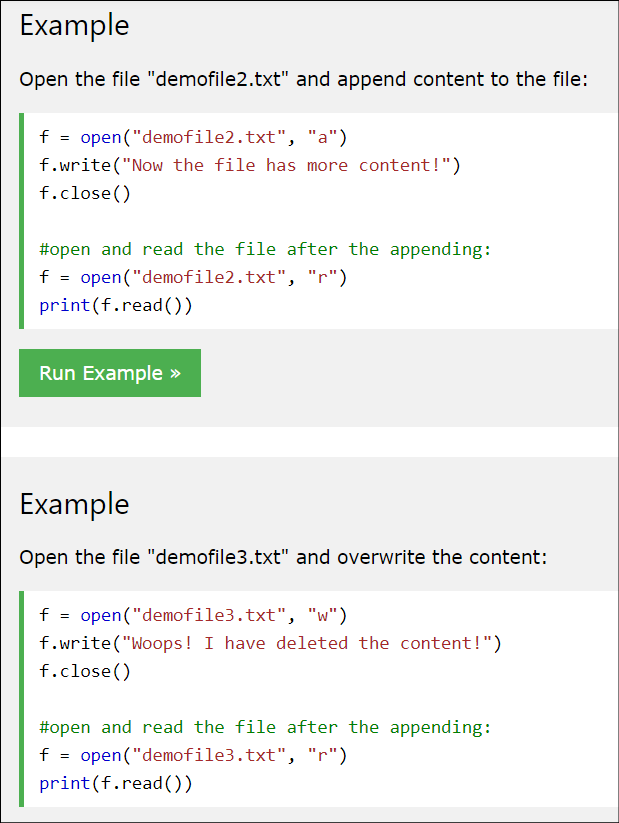
So based on this information, if we want to print our items into a text file, we use this script:
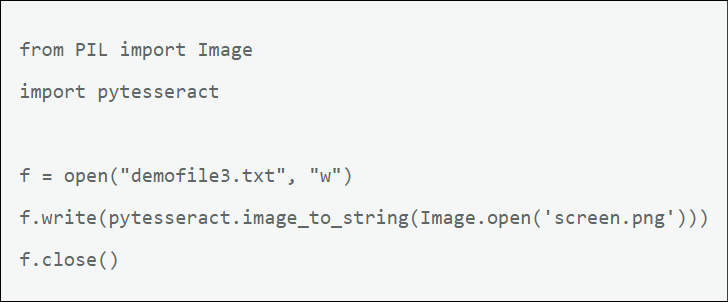
The resulting text file looks like this:
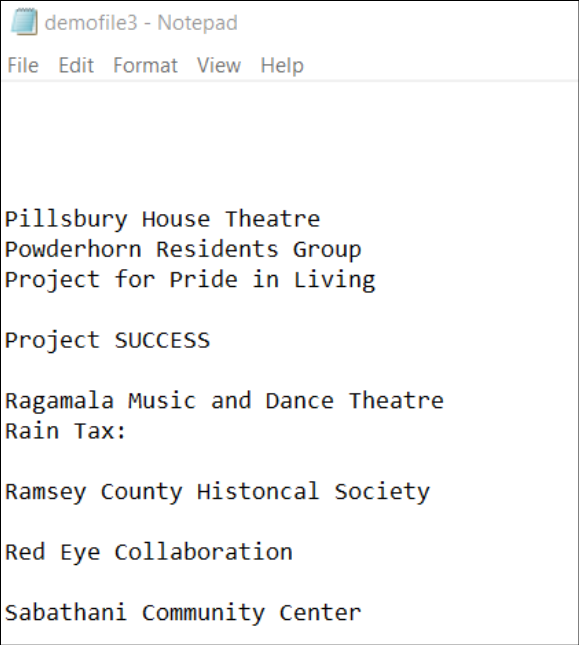
That’s it! You're done!
Written By Tom Caliendo
Researcher at Archangel Technologies / Freelance Writer
