OSINT & OPSEC: Short URLs
Learn how to OSINT investigated URL short links and link tracking.


We are going on a journey with URL shortening services to investigate short URLs and link tracking, a small trip in the strange world of short links with an OSINT investigator as your guide.
URL shortening services have been around for a long time. The Wikipedia page for URL shortening states a patent filed back in 2000 that describes the concept of “[…] providing links to remotely located information in a network of remotely connected computers”. With social media and instant messaging, URL shortening services are now more useful than ever to help us remember short addresses instead of 3 lines of letters that would count as 64 SMS or 10 tweets. Too much, I know…
Shortening URLs is quite simple…
You take a long URL like:
https://www.thisisareallyreallyreallylongurl.com
and you use an online service like Bitly or TinyURL and get a short, unique URL like
https://bit.ly/ShOrTuRl
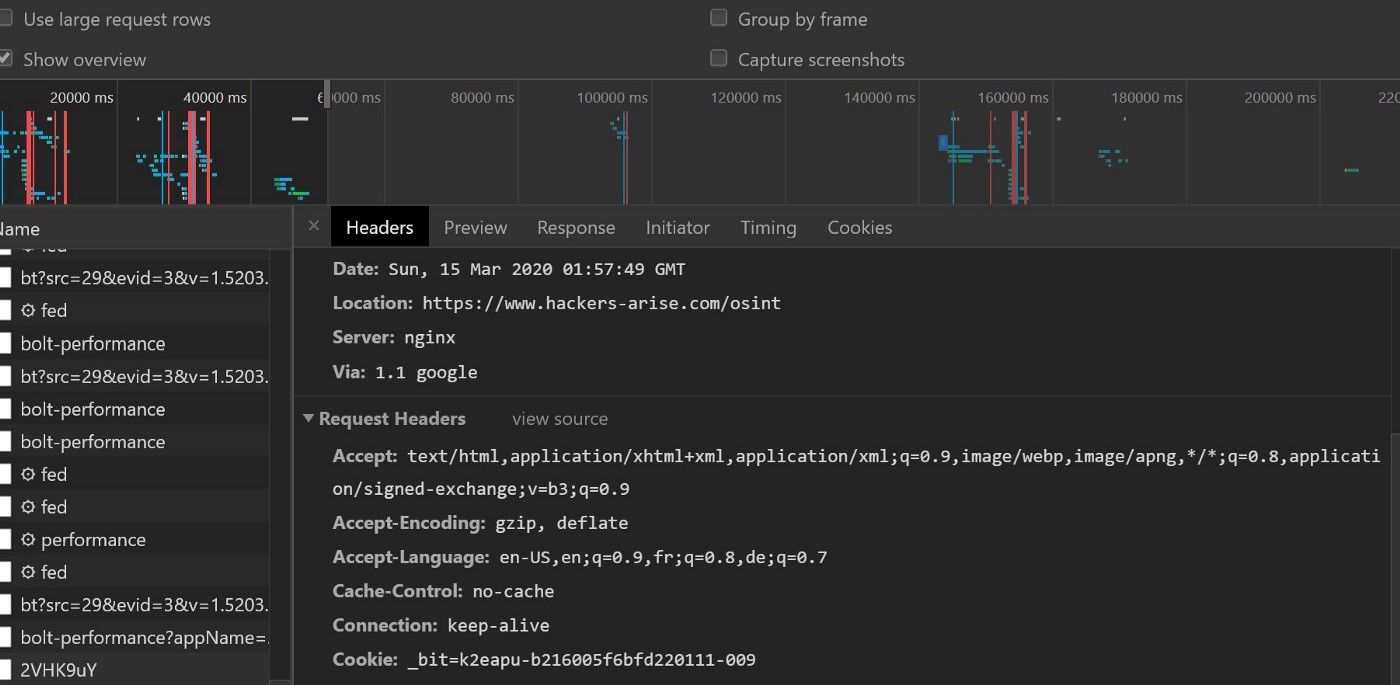
The “ShOrTuRl” part works as a unique key that the server can use to specifically redirect the request to the chosen final URL. There are different methods used when redirecting a browser from an URL to another one. The instructions are usually sent in the header of the page with HTTP status 301 (Moved Permanently), 302 (Found), 307 (Temporary Redirect) or 308 (Permanent Redirect) [ref: https://developer.mozilla.org/en-US/docs/Web/HTTP/Redirections]. The destination of the redirection is usually encoded in the “Location” header field.
Ex: Location: http://www.example.org/index.php)
Some code in the page can also be used to create a redirection.
But redirecting is not the only thing that happens when your browser goes on the server. It also leaves a entry in the logs with it’s own fingerprint containing the IP address, the user-agent and every thing a browser accepts to give to a server asking nicely (if you don’t know anything about browser fingerprinting, go check the EFF’s Panopticlick project). These additional elements add power to URL shortening and help marketing, SEO, and other “spying on customers” teams to get analytics information on who’s using their websites. The information (or should I say intelligence) gathered can be quite granular.
If you need more security or anonymity, you can find online services that can add link expiration dates or passwords (like https://itsssl.com/ or https://www.hidelinks.com/).
You probably don’t trust online services when it comes to more private or “serious” matters. So there are plenty of alternatives to online services, alternative software and techniques you can host yourself. You can then enjoy your own redirecting service. You will need more resources though.
First, find a server that can host a web server. VPS are cheap nowadays, that’s the easy part ( https://www.techradar.com/news/best-vps-hosting).
Then, you will need to find a domain name that you can link to the IP address of the server you just rented. That’s the tricky part. Short domain names are not easy to find (there’s a domain names market!). If you don’t have a lot of money, I strongly suggest that you use a dynamic DNS service like https://dyn.com/ or https://www.noip.com/. They have short domain names available (*.hopto.org, *.is-by.us, *.dynalias.org). You just need to create an account, choose a domain, choose a subdomain and there you go, xxx.hopto.org goes to your server!
Now you can go full manual and install a web server and web pages with some HTML or PHP code to do the redirect and the logging if needed. The following lines will log the requesting IP address, the port, date, time and the user-agent of the browser to a file named log.txt
<?php
$file = “log.txt”;
$ip = $_SERVER[‘REMOTE_ADDR’];
$port = $_SERVER[‘REMOTE_PORT’];
$date = date(“d.m.y”);
$time = date(“H:i:s”);
$browser = $_SERVER[‘HTTP_USER_AGENT’];
$data = “IP: “.$ip.”:”.$port.”, Date: “.$date.”, Time:”.$time.”, Browser: “.$browser;
$f=fopen($file, ‘a’);
fwrite($f,$data.”\r\r\n”);
fclose($f);
header(“Location: https://www.marvel.com/");
exit;
?>
Then the browser will be redirected to the “Location”, https://www.marvel.com/.
If you create a uniquely named php file and replace “log.txt” with a unique name, you have a system with multiple redirecting links with some basic tracking. Dirty yet simple and efficient. Believe me.
I have tested two other ways to host your own redirecting/shortening service: YOURLS and … WordPress!
YOURLS website says it all: “YOURLS stands for Your Own URL Shortener. It is a small set of PHP scripts that will allow you to run your own URL shortening service (a la TinyURL or Bitly)”.
I am not going to cover the installation process but you end up with a nice interface, very much like Bitly. And as it is your own server, you can log whatever you deem necessary.
Going the Wordpress way is easy. Even if my intent is not to write a guide on creating that kind of service but after you have installed Wordpress on your web server, you will find the basic steps here: Beginner’s Guide to Creating 301 Redirects in WordPress (Step by Step). If you want more logging capabilities, check plugins like Slimstats. OK, I agree: not much shortening with this trick but of course, there are plugins for that: URL Shortener or some others here. I did not test them so I can’t really describe how they perform.
Now because you are using your own domain name, security systems might flag your links as potentially malicious. That’s probably one of the many reasons why phishers still use “standard” services like Bitly or TinyURL. Which, by the way, made URL shortening services more scrutinized by IT security firms!
So, the bad guys are using URL redirecting/shortening to trick users and protection systems into going to malicious websites. And on the White side of the hat, we use tracking links to find bad guys and test our beloved users.
When we are in the intelligence gathering phase and using social engineering against our target we may have to resort to “active OSINT” (or aggressive OSINT as we call it around here), meaning that we may use techniques that will expose information that’s available but not directly accessible. Like an IP address.
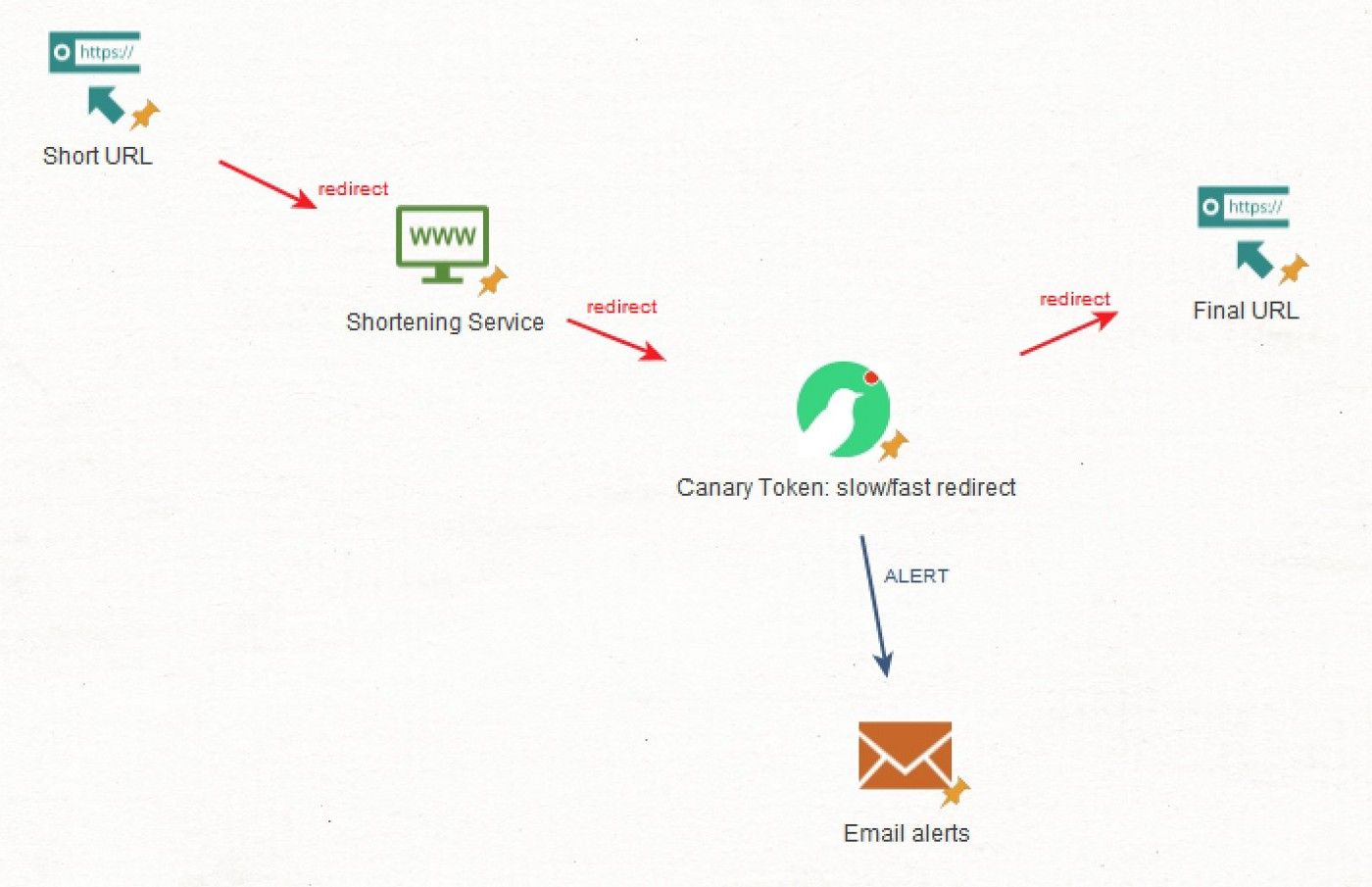
Let’s say you have to send a link to someone to get a full user-agent and an IP address. Let’s say that you cannot use a custom domain name due to safety restrictions on the target’s side. If you want to send a malicious link but still need to use Bitly or TinyURL, you can use a “double redirect”. You send a short URL that redirects to a tracking service that will gather information about who and what clicked the link and finally redirect to an URL that will appear innocuous.
Here’s a schema of how it would work.
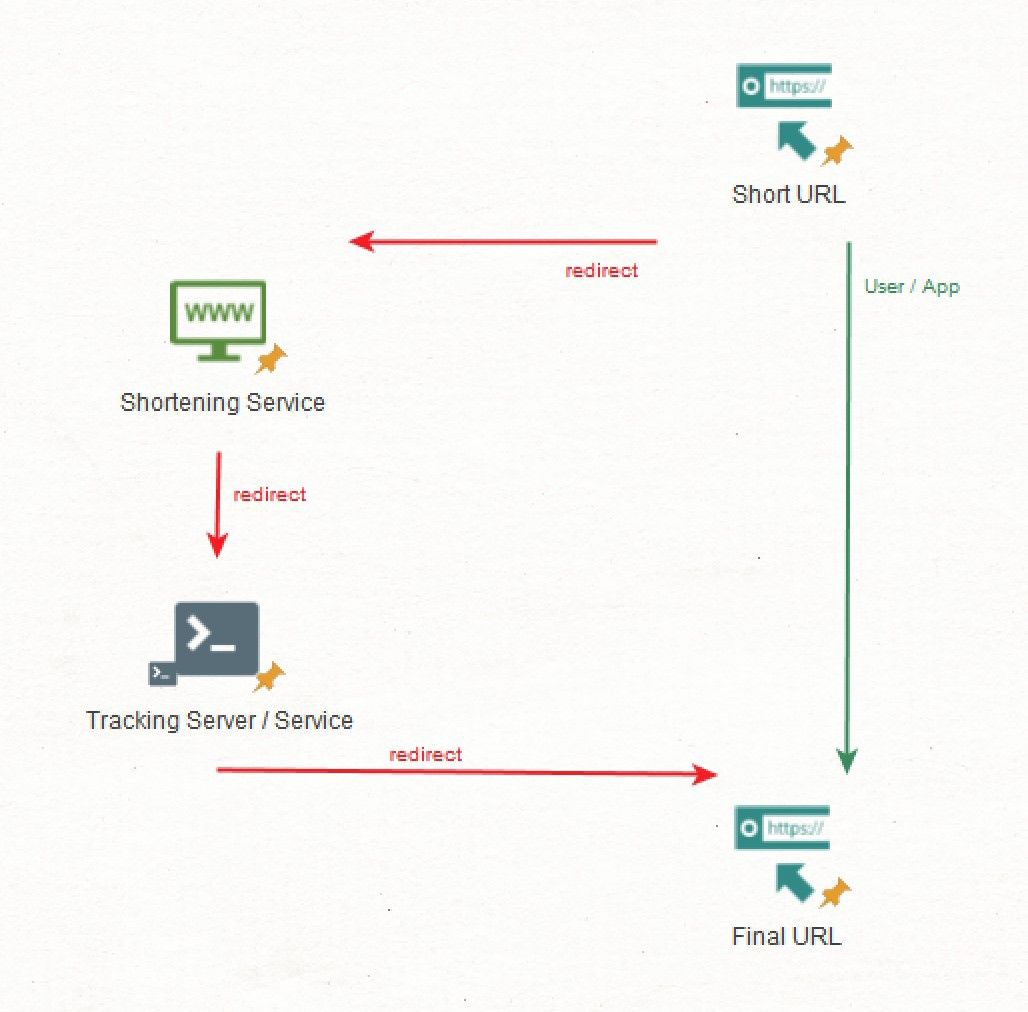
Most social media, messaging app and other apps with nice UI will try to get to the last redirect to present the user with the end result of the short URL. This is actually a great flaw to exploit and an even bigger security issue when it comes to social engineering because your “url-in-the-middle” is usually not shown to the user.
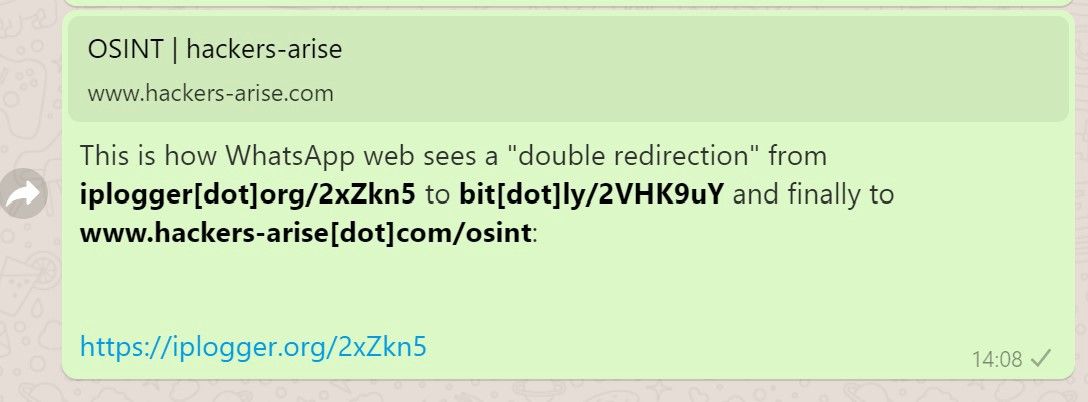
If you don’t have a server you can use for the middle URL, there are tons of options available online. Websites like https://iplogger.org/, https://grabify.link/ or https://blasze.com/ will do the tracking for you. I still prefer to use a dedicated VPS in a country far away from mine but if I have to choose, my favorite third party Canary Tokens, those small pieces of code that every IT security guy loves (if you don’t know what I am talking about, head here). There are slow and fast “Canary tokens redirects” that will send you email alerts when they are activated. Neat.
Investigating these links is not rocket science.
Thanks to URL expander services like http://checkshorturl.com/ or http://urlxray.com/. You can also use more advanced websites like https://httpstatus.io/ to check the header of the page and try to find the “Location” field.
Most of the URL shortening services have also created ways of getting some information about the destination the short URL is pointing to:
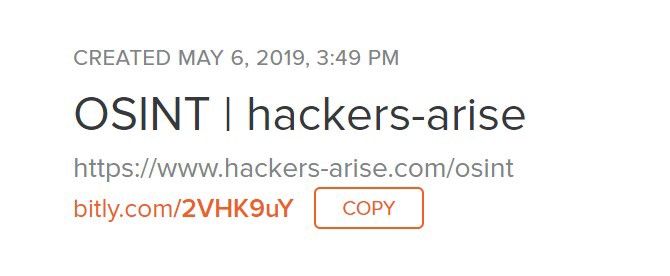
Bitly
Easy enough, you just add a “+” at the end of the short URL
Ex: bit.ly/2VHK9uY+
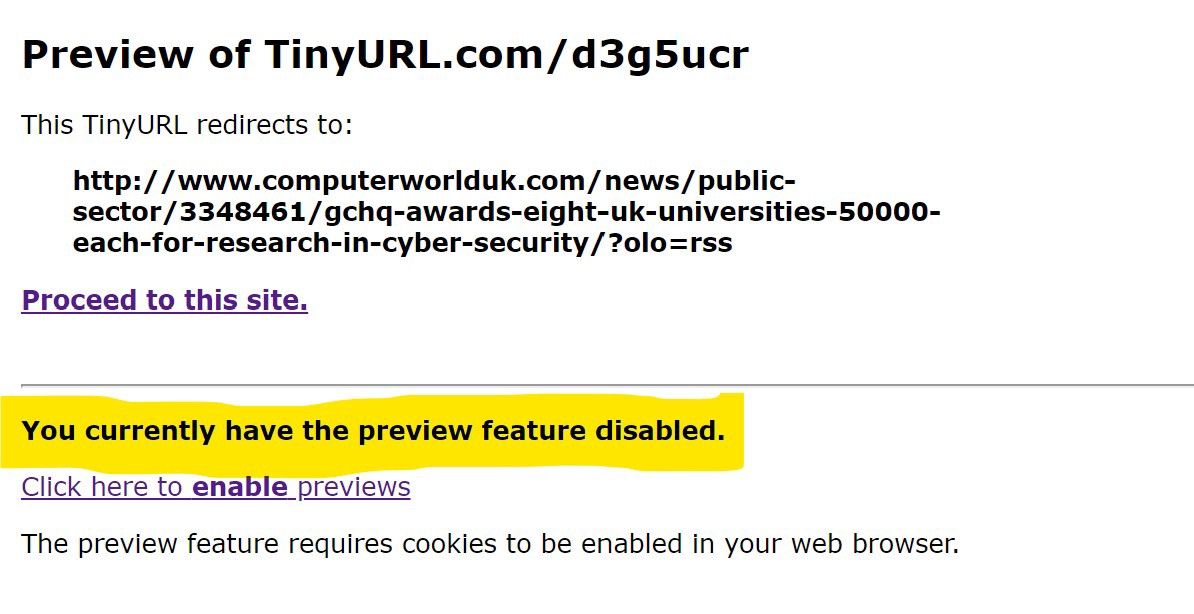
TinyURLS
Add “preview.” before “tinyurl”
Ex: http://preview.tinyurl.com/d3g5ucr
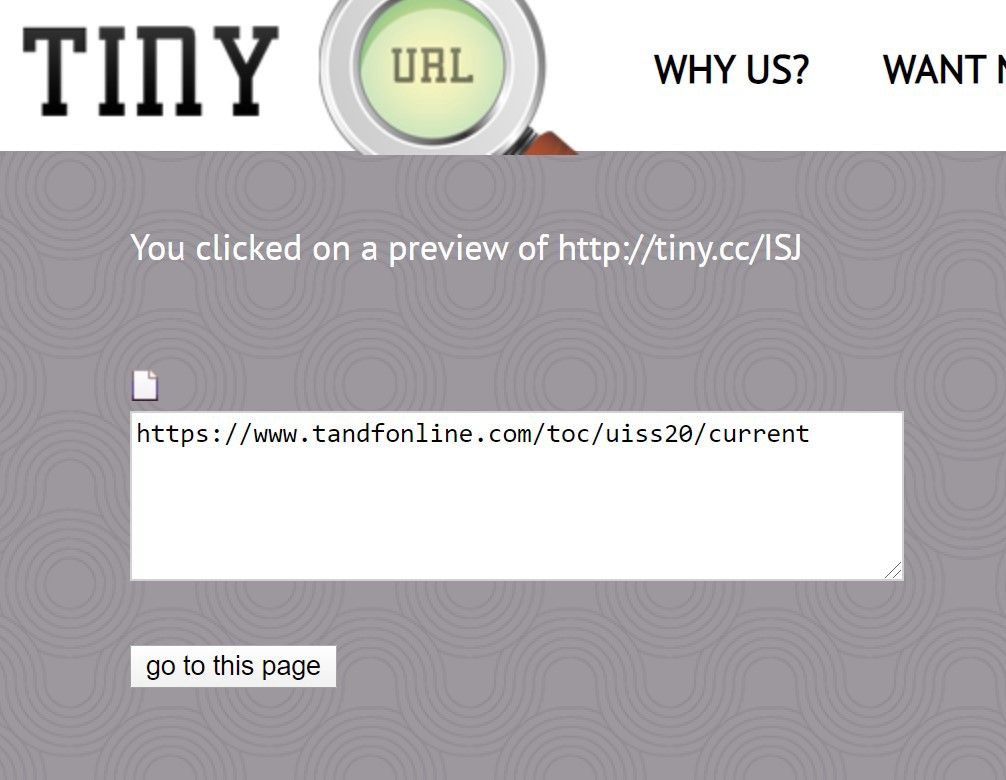
tiny.cc
Another service, another method: add “=” at the end of the URL
Ex: https://tiny.cc/ISJ=
Note that if you add "~" instead of "=", you will access to stats for the URL.
bit.do
Just add a “-” at the end.
No example, bit.do gives easily access to the IP address ;)
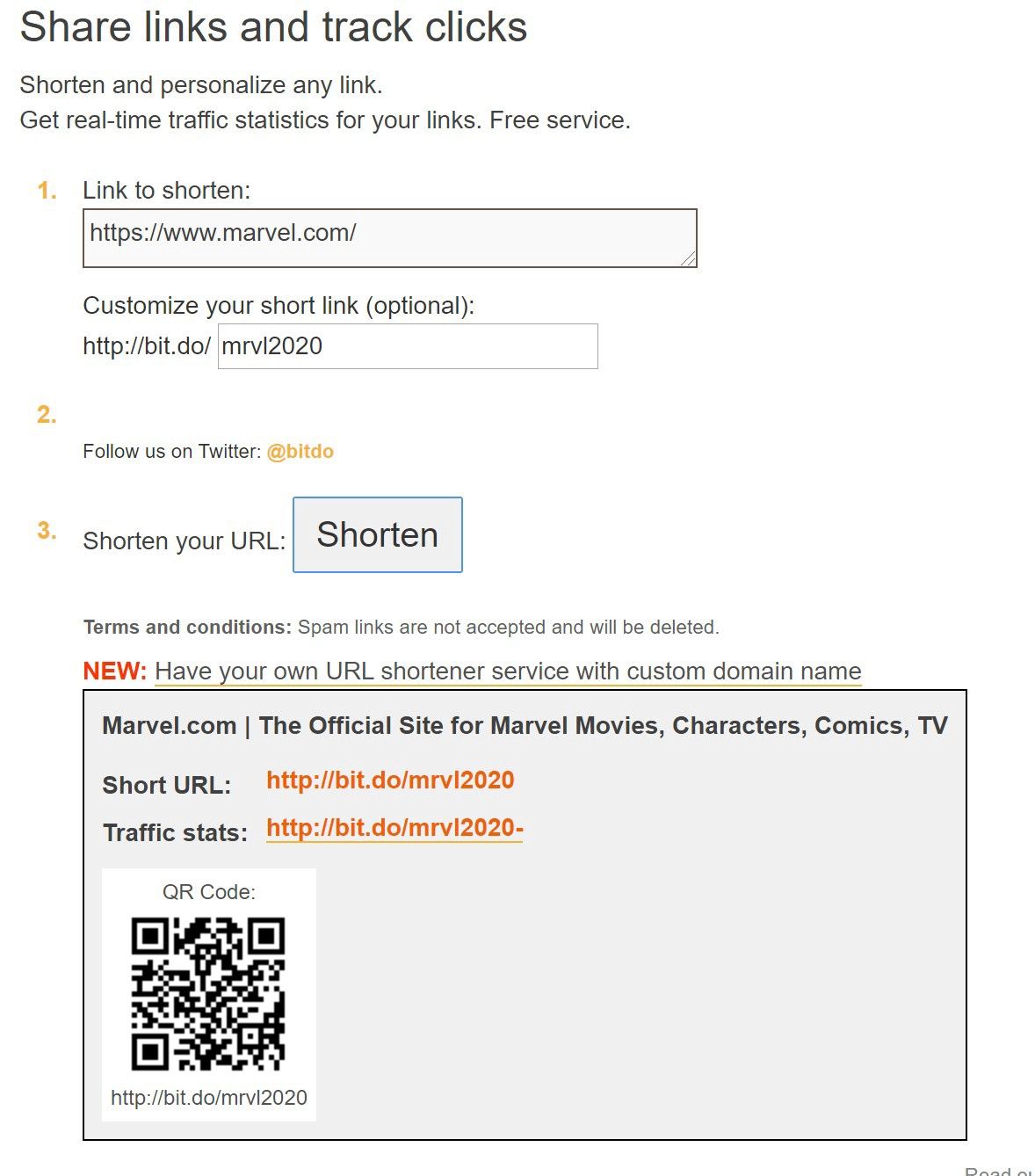
Now, using these online services may be good enough. But there are several problems with the URL expanders method and the preview method.
The preview trick gives stats for specific services only. If you face a service that does not provide such possibility, you have to go for an URL expander. And most of them want to show you the final URL you will be accessing. If there’s a tracking URL in the middle you will not know nor see it.
Also both techniques will usually follow the link of the expanded URL. If I’m the bad guy and I’m setting a honeypot to check when good guys are investigating some short URLs, I will know when they use online services to expand them. (Note: By default, the preview technique for TinyURL does not preview the URL. Check the highlighted part in the picture above).
If you really want to check the short URL carefully, you will have to peel the different layers and choose if you want to follow a link that may reveal information about you.
LinkPeelr will do that for you. If you enter the URL and click “Peel” it will show you the URL you would be redirected to, without touching it.

But again, there’s a small problem: most of the time, the redirection is triggered by a field in the header of the page. You can actually use many other ways of redirecting the user to another web page. You can use Java for example, like the “Slow Redirect Canary Token” does. It means that none of the tools we already discussed will be able to find the final URL because they all check the header in the web page to find 300s status code and “Location” field.
When Java is telling the browser to go to another location (with window.location for example), it’s not in the header part of the page.
This is getting frustrating. But enters cURL, the oldest tool in the arsenal of IT guys! cURL will allow us to peel layers of redirections and if you want to do so, it will also be able to GET the code that’s responsible for the redirection. If it’s in the header, it’s easy enough. If there’s some code, cURL will see it.
I won’t insult Linux/Unix users by saying that cURL is already included in their OS but Windows users, rejoice: cURL has been included in Windows 10 since build 17063!
So here’s the line you may use to investigate suspicious URLs:
curl -svI URLTOCHECK --max-redirs 0 --user-agent "Googlebot/2.1 (+http://www.google.com/bot.html)"
URLTOCHECK is the URL you have to…check!
-s is for silent (no download stats)
-v is for verbose
-I is for “fetch only the HEADER” — remember? most of the redirections are handled in the HEADER
— max-redirs 0 sets the maximum numbers of redirection we want cURL to follow.
— user-agent create the user-agent, the fingerprint that cURL will sent when requested by the webpage
When you run this command, cURL will fetch the page at the URLTOCHECK address and grab the header. If there’s a redirection it will not follow it and it will say “hey, I’m a Google bot” when asked.
(You can check Google and Yandex bot user-agent strings here: Google & Yandex).
Let’s use this technique on the examples above:
PS>
curl -svI bit.ly/2VHK9uY --max-redirs 0 --user-agent “Googlebot/2.1 (+http://www.google.com/bot.html)"
* Trying 67.199.248.11…
* TCP_NODELAY set
* Connected to bit.ly (67.199.248.11) port 80 (#0)
> HEAD /2VHK9uY HTTP/1.1
> Host: bit.ly
> User-Agent: Googlebot/2.1 (+http://www.google.com/bot.html)
> Accept: */*
>
< HTTP/1.1 301 Moved Permanently
< Server: nginx
< Date: Sun, 15 Mar 2020 00:24:06 GMT
< Content-Type: text/html; charset=utf-8
< Content-Length: 122
< Cache-Control: private, max-age=90
< Location: https://www.hackers-arise.com/osint
< Via: 1.1 google
<
* Connection #0 to host bit.ly left intact
We easily find the “Location” field and we can check the redirection. Also note the 301 status a few lines above.
You may also add
| grep Location
on Linux
or
| Select-String -Pattern "location"
on Windows to highlight the redirection:
PS> curl -svI https://tiny.cc/ISJ --max-redirs 0 --user-agent “Googlebot/2.1 (+http://www.google.com/bot.html)" | Select-String -Pattern “location”
* Trying 192.241.240.89…
* TCP_NODELAY set
[…]
> HEAD /ISJ HTTP/1.1
> Host: tiny.cc
> User-Agent: Googlebot/2.1 (+http://www.google.com/bot.html)
> Accept: */*
>
[…]
< HTTP/1.1 303 See Other
< Server: nginx
< Date: Sun, 15 Mar 2020 00:33:12 GMT
< Content-Type: text/html
< Connection: keep-alive
< X-Powered-By: PHP/5.3.28
< X-Frame-Options: sameorigin
< Access-Control-Allow-Origin: *
< Set-Cookie: main_session=[…]; expires=Mon, 16-Mar-2020 00:33:12 GMT; path=/; domain=.tiny.cc; secure; httponly
< X-Robots-Tag: nofollow, noindex
< Location: https://www.tandfonline.com/toc/uiss20/current
<
* Connection #0 to host tiny.cc left intactLocation: https://www.tandfonline.com/toc/uiss20/current
Works well but wait…What? “< HTTP/1.1 303 See Other”???
Let’s check “RFC 7231 Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content” :
“The 303 (See Other) status code indicates that the server is
redirecting the user agent to a different resource, as indicated by a
URI in the Location header field, which is intended to provide an
indirect response to the original request.”
OK, whatever…
So, now I know where the short URL goes and I can take time to evaluate the risk of following it. If I want to follow it, I can manually change the URLTOCHECK to the one I found in the “Location” field. And repeat the process for every layer I peel out.
If you want cURL to go crazy, add a “-L” and indicate “-1” as — max-redirs and cURL will try to follow all the redirections.
curl -svIL https://tiny.cc/ISJ --max-redirs -1 --user-agent “Googlebot/2.1 (+http://www.google.com/bot.html)" | Select-String -Pattern “location”
Another thing. The featured image was not chosen because it’s black and nerdy. OK, it was but it also illustrates the idea that you can use the Developer tools in a browser to get the headers and find the final URL. But it means you have to actually enter the short URL in your browser and follow it. I really prefer to not involve this fragile piece of software during this first phase!
Also, could we script this? Probably but for the moment I prefer the security of manually changing the URL. It lowers the chance of a dangerous link to be followed.
What if the redirect method is not in the header? Then you will have to be creative and think about the options I passed to cURL. I will let you discover this with the following short URL:
You have to understand that following this links will be logged. Not that I will do anything with these logs but I thought you should know!
