TryHackMe: Web OSINT Writeup
Learn the basics of gathering information related to websites using open-source Intelligence research.


Learn the basics of gathering information related to websites using open source intelligence research with this fantastic TryHackMe challenge.

Open Source Intelligence Gathering plays a vital role for security researchers, Ethical Hackers, Pentesters, Security Analysts, and of course Black Hat Hackers. OSINT helps in collecting and analyzing information from publically available resources for intelligence purposes.
To get an idea of what Open Source Intelligence Gathering looks like, we are going to walk through the TryHackMe room "Web OSINT". This room targets gathering information related to websites. So without further ado let's dive in.
P.S: I highly recommend you folks to try solving the room on your own, in this way you would be able to enhance your reconnaissance skills and fill in the gaps where you lack.
Objective
Use different publically available tools to gather information related to the target website
Task 1
When A Website Does Not Exist
When finding your desired information related to a business, we usually use google. Consider a scenario where you have to find some information and the target website no longer exists. What would you do ??? We will get to know this when we solve this particular challenge in which we have to gather some data related to a website called "RepublicOfKoffee.com". The google search shows the following when we try to navigate to this website
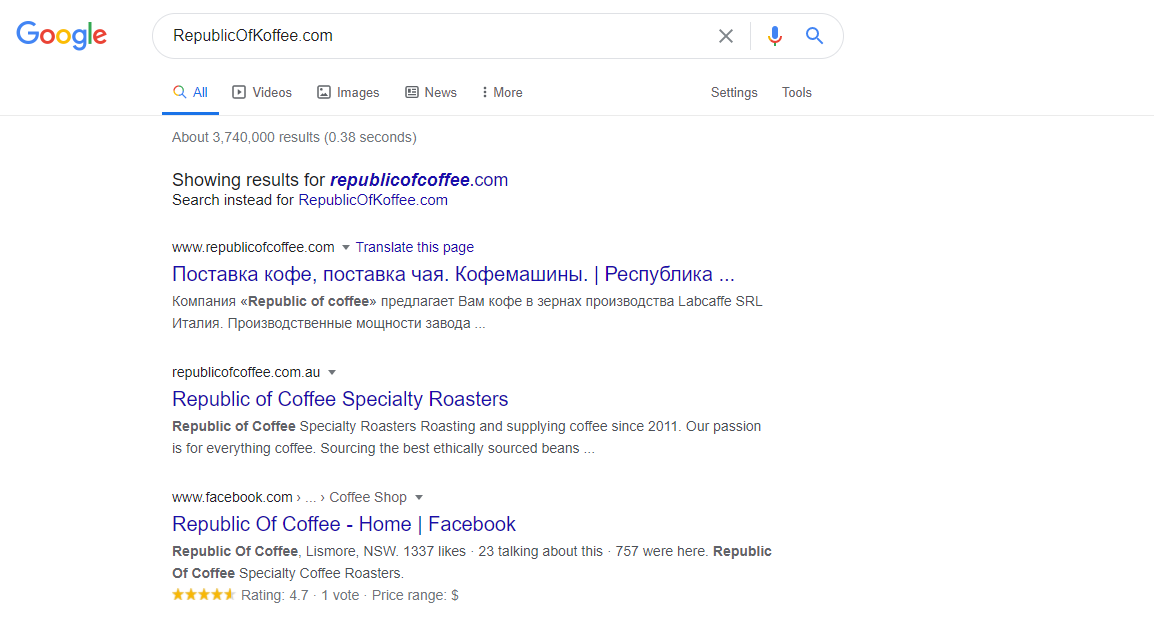
The website does not exist but even if it does not exist we might be able to pull out some information.
Task 2
Whois Registration
Since we did not find anything by searching our target website, we can still find the information related to the website by using a tool called lookup.icann.org. There are a lot of other tools too from which you can extract information such as who owns the domain, the nameservers, phone number, email addresses, city/country, etc.
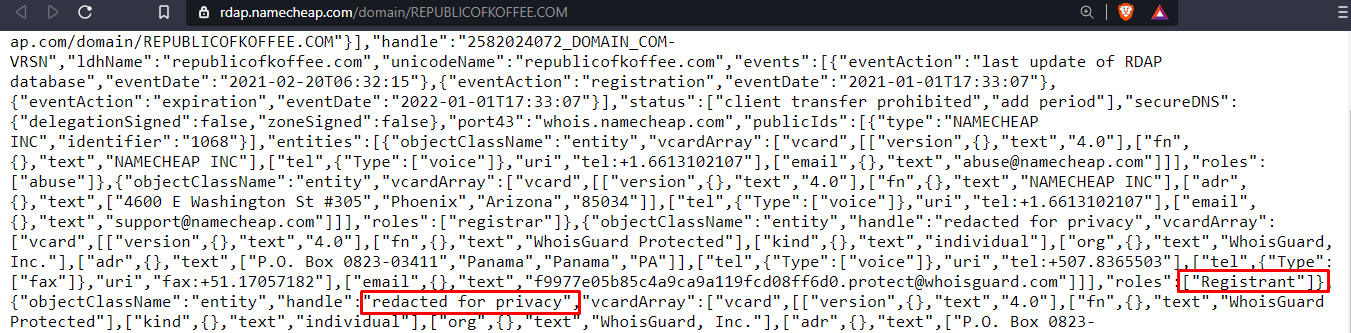
Navigate to the online tool we mentioned above and find the required information i.e. name of the company the website was registered with, phone numbers, name servers, name of the registrant, and the country of the registrant.
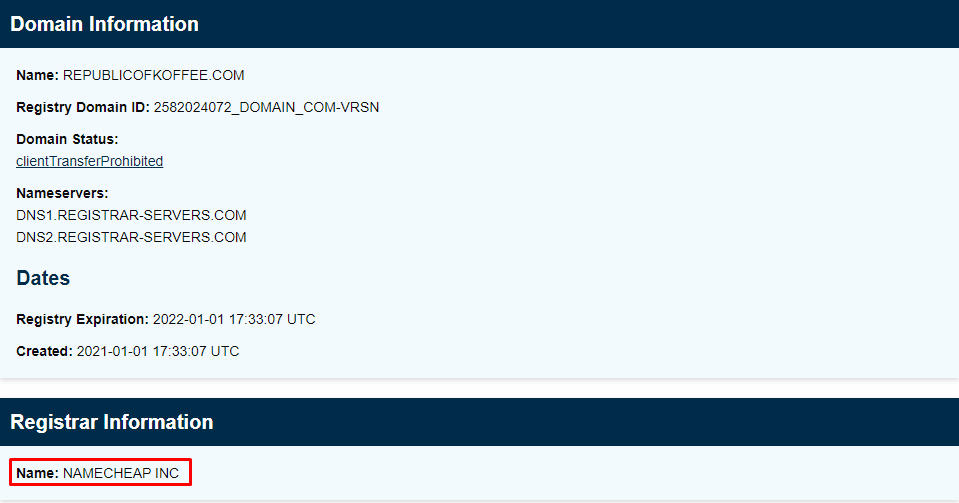
We come to know that the domain was registered by company called
NAMECHEAP INC
Similarly, we can find the phone number, name servers, name of the registrant and the country of registrant as seen below
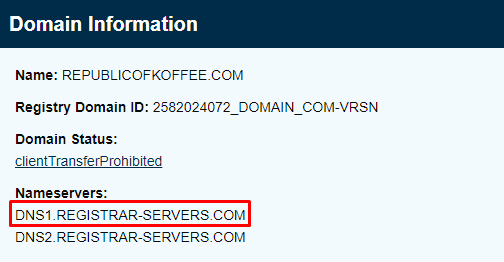

Task 3
Ghosts of Webistes past
Now that we have the basic information related to the website extracted from the publically available tool. Having said that, let's find out what the website looks like even though the website does not exist.
We are going to utilize the waybackmachine which holds archives of websites at different times of the year.
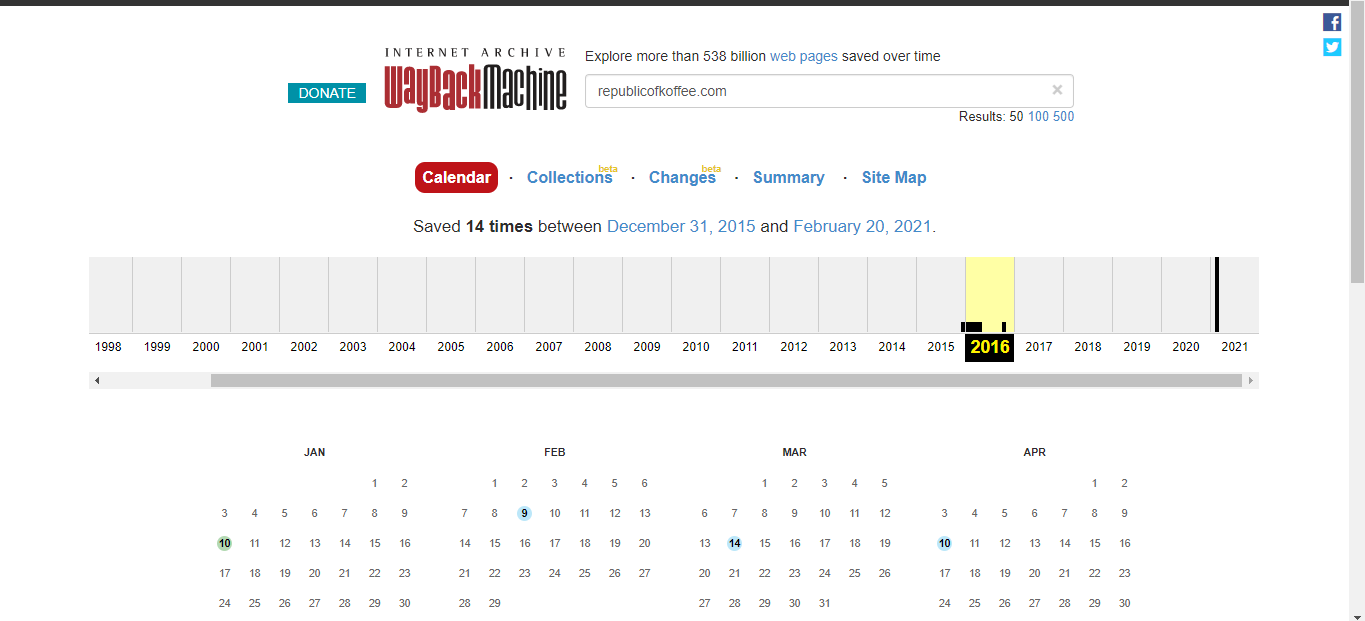
We need to find the name of the author for the very first blog that was written on the website.Navigate to the very first archive we find on the timeline of the wayback machine
Author of the blog
Steve
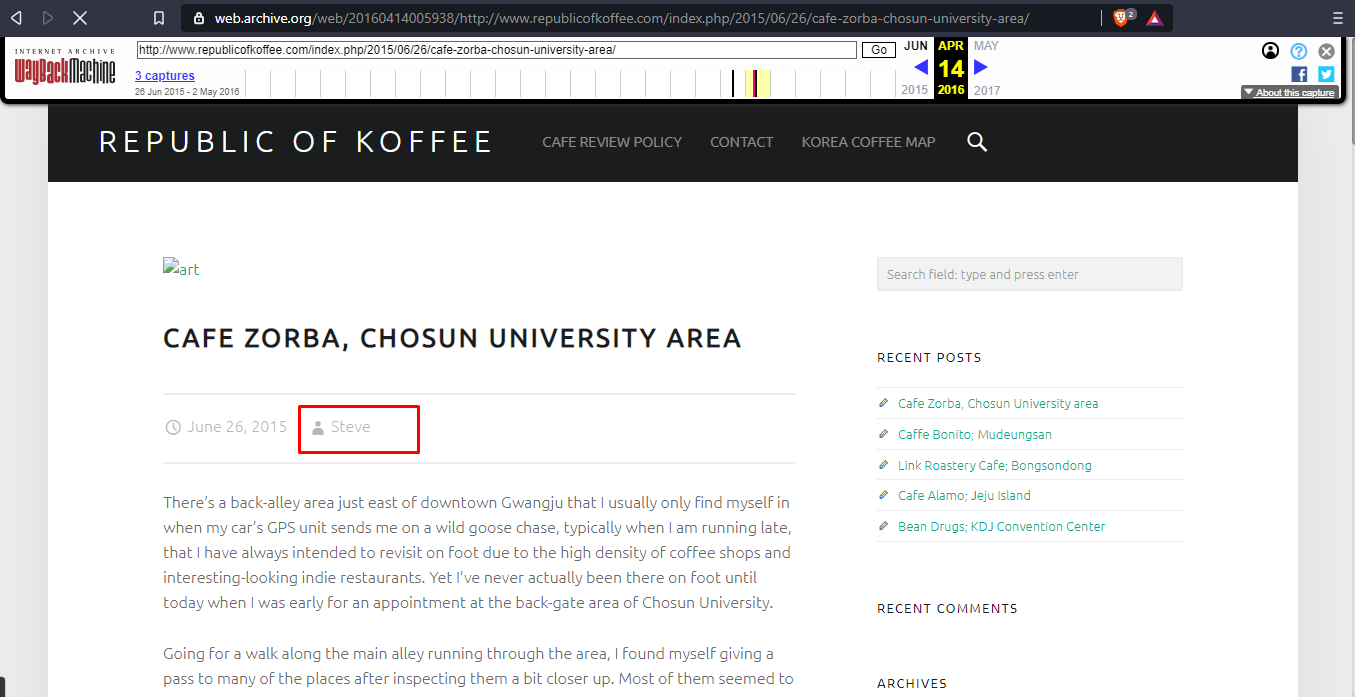
Next, we need to find the country from where the author is writing. Time to test our Recon skills. We know the city name and the place as mentioned in the blog, doing a little research we find the country
Country Name : Gwangju, South Korea
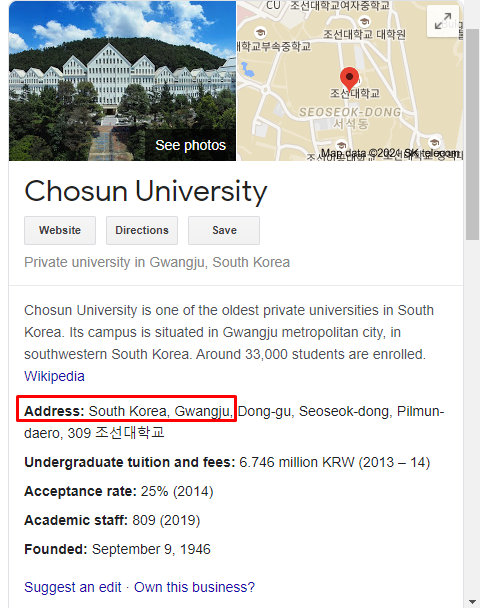
Navigate to the next blog , where we need to find out the name of the temple the author visits
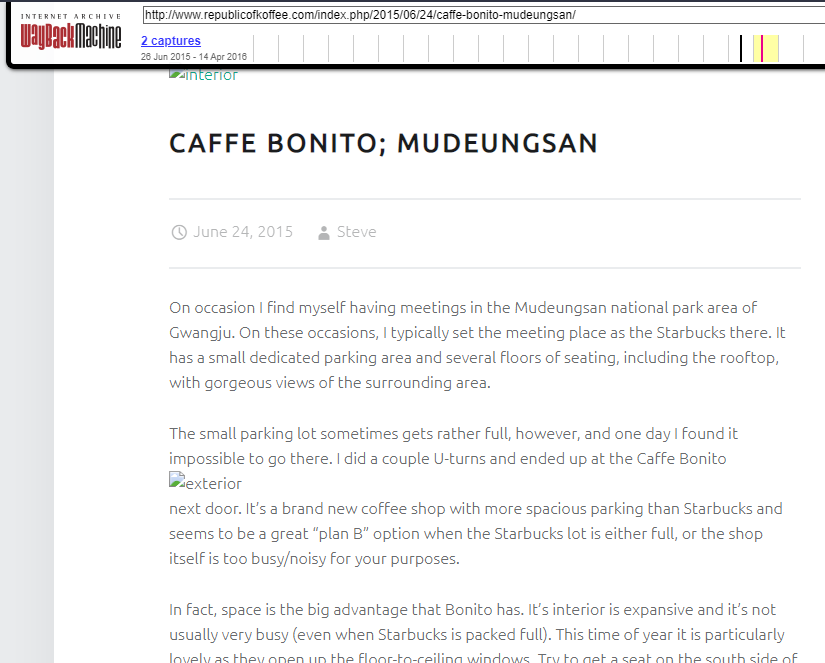
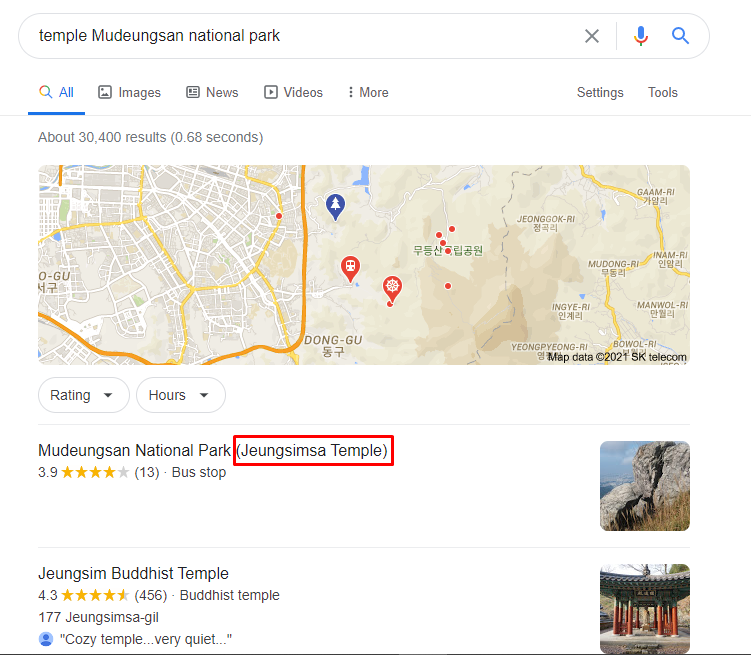
Doing a little recon on the places mentioned in the blog we find the temple name as seen below
Temple Name: Jeungsimsa Temple
Task 4
Digging into DNS
Till now we have gathered enough information that could be used to draw some conclusions. We need to find more technical details related to the website such as the IP address, the type of hosting the website was using.
Using the ViewDns info we can gather a lot of information related to a website
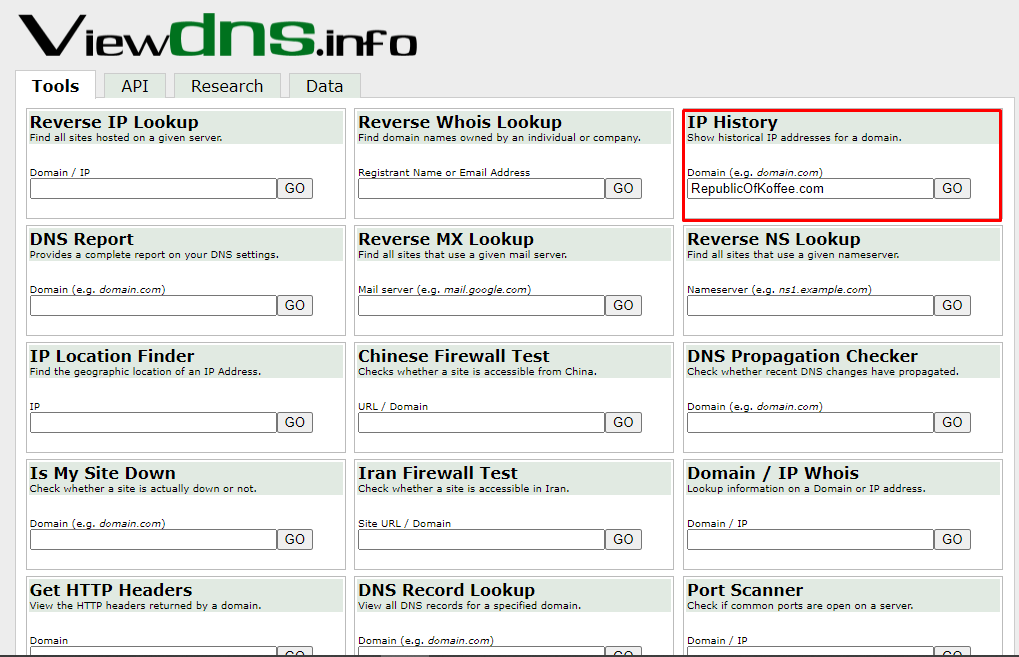
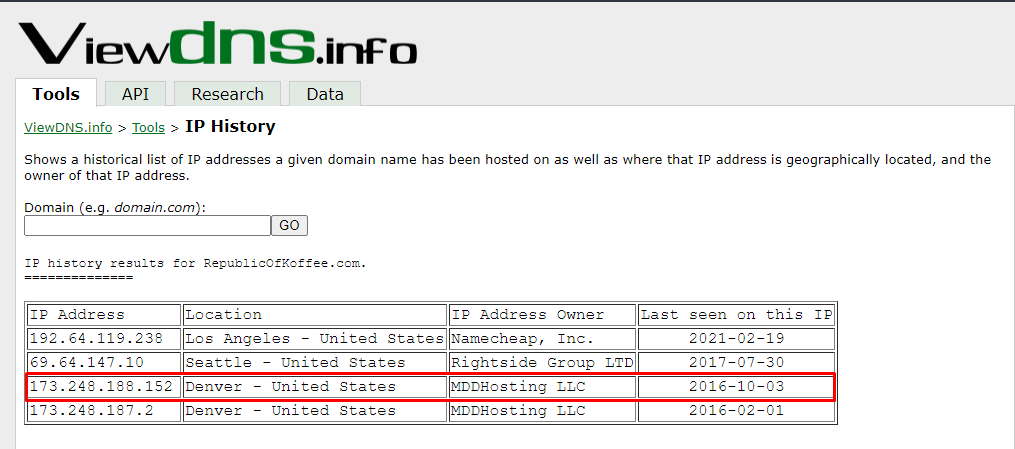
The next thing that we need to find is the RepublicOfKoffee.com's IP address as of October 2016. Use the IP history to extract the required information
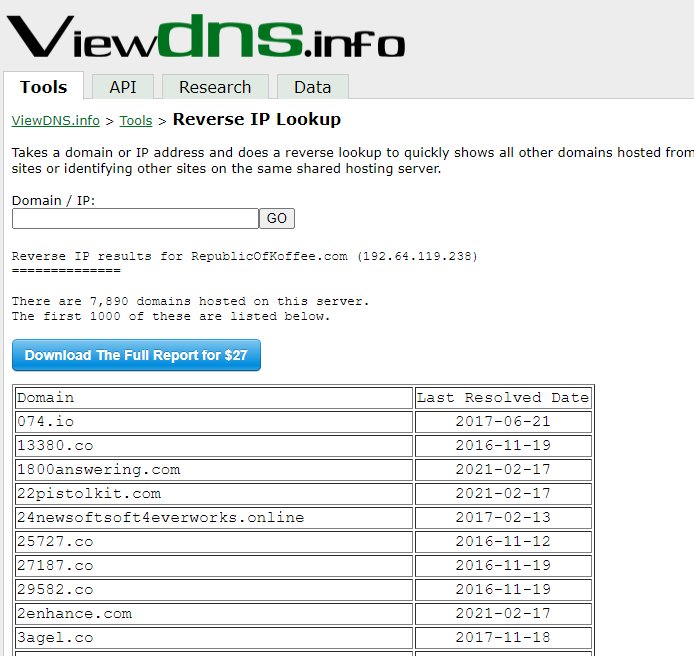
Now we need to find out hosting service our target uses. Using the reverse lookup for this purpose. There is a long list of domain names associated with the IP we found earlier. This means our target website owner is using a shared hosting service as it costs a lot less than the dedicated hosting service
Going back to the IP history, the IP address has changed 4 times in the history of the domains. This answers the last answer of this task
Task 5
Taking off the training wheels
We have a new target domain heat.net. We are required to find following
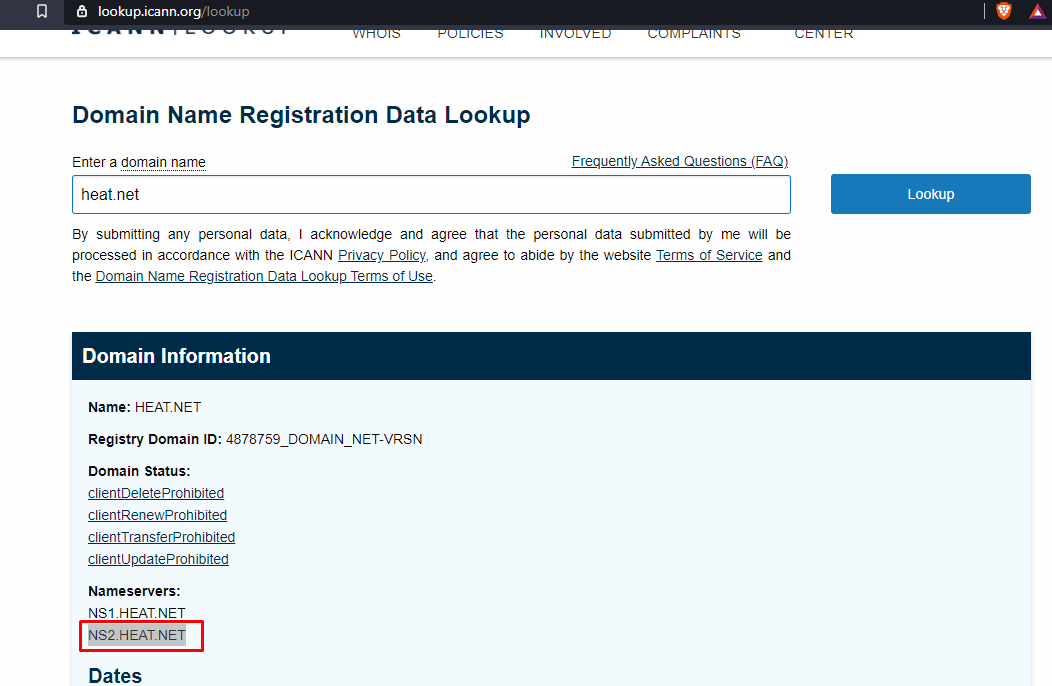
Second name server
The IP address of the domain that was listed on as December 2011
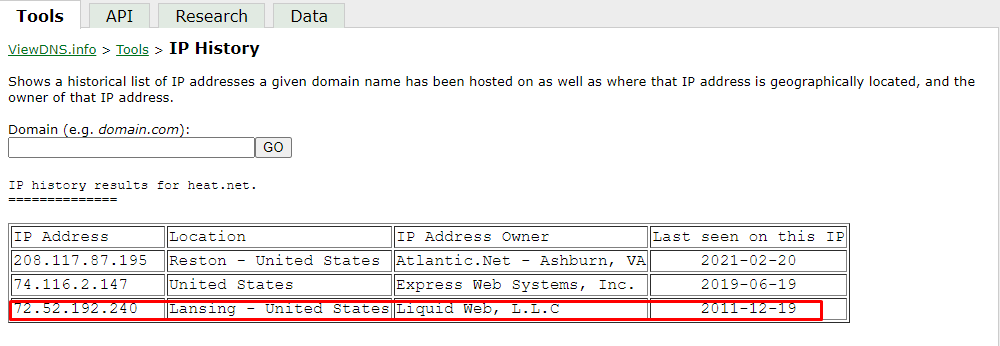
Hosting service the domain owner is using
A shared hosting service is being used by the domain owner
Date of first site captured by Internet Archive
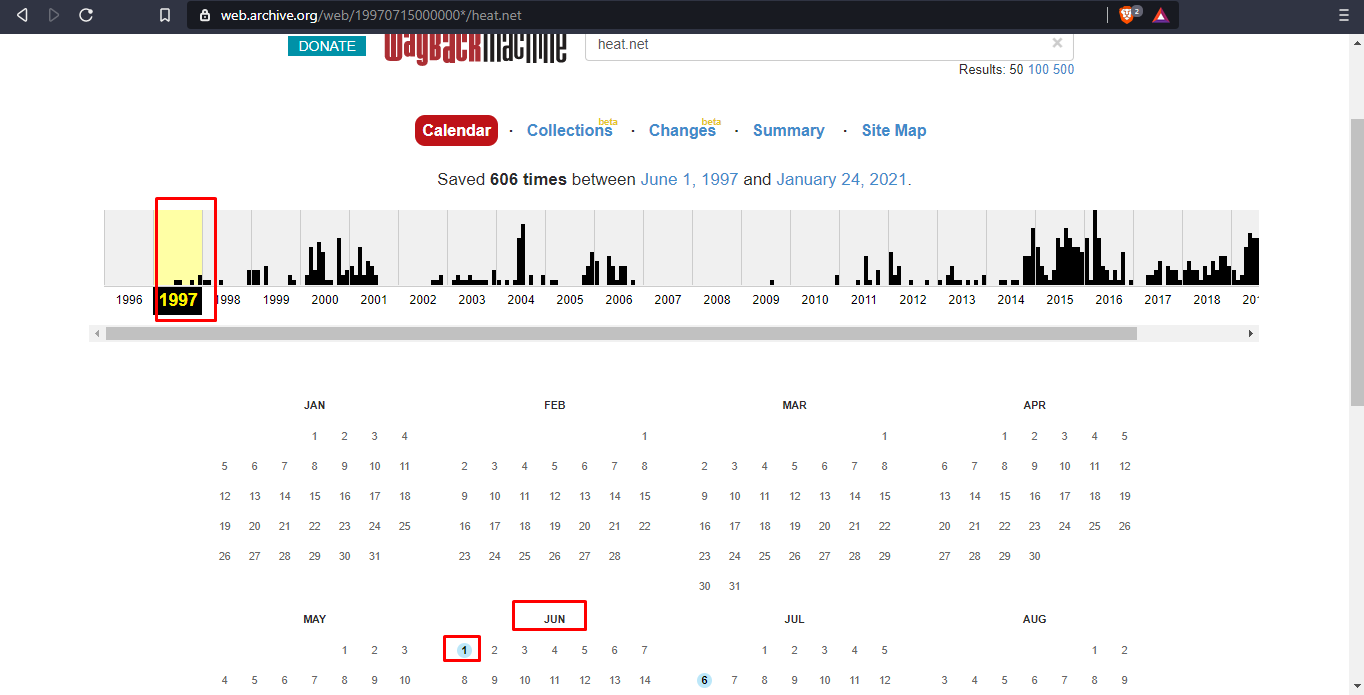
First sentence of the first paragraph from the final capture of 2001
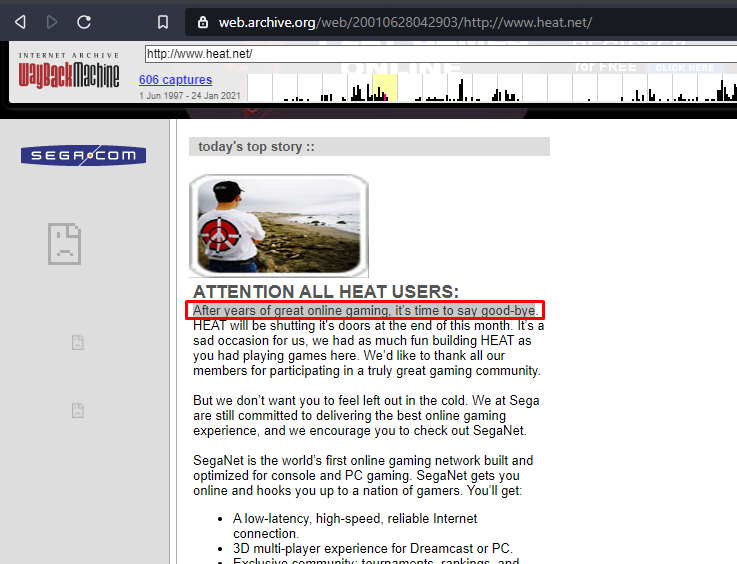
Company responsible for the original version of the site
SegaSoft was the company responsible for the original version of the site
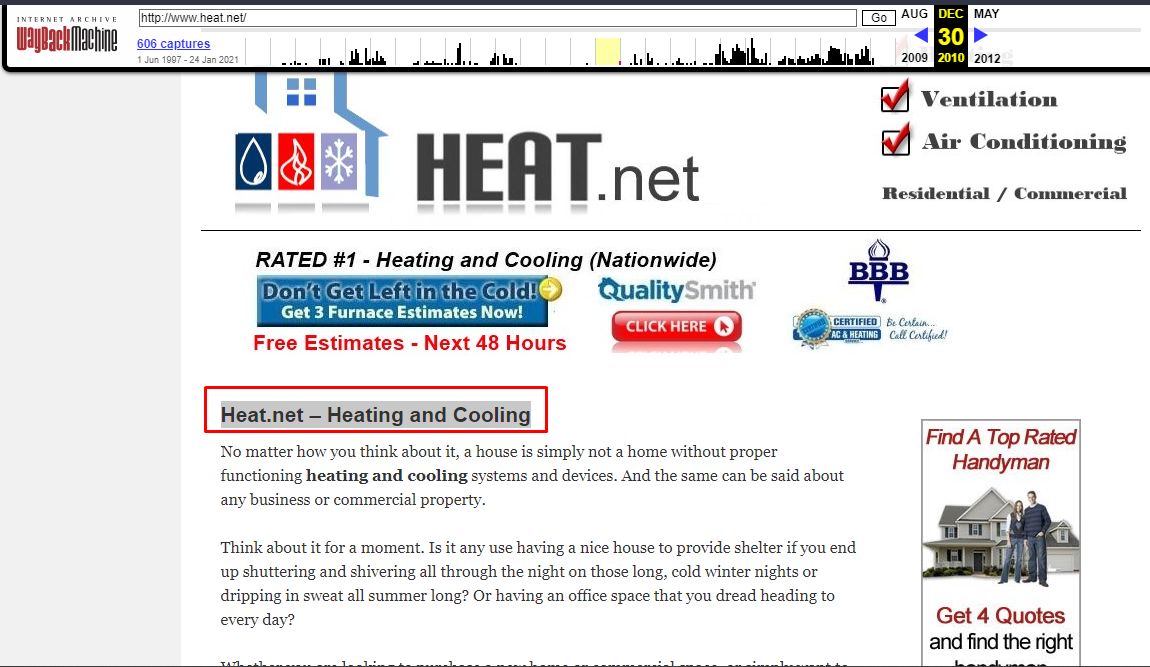
First header of the last site captured on 2010
Task 6
Taking A Peek Under The Hood Of A Website
To join the connecting dots, every aspect of the target under investigation has to be considered. Websites remaining dormant for a long time and then coming back online raise different concerns. To verify that the website is legitimate some points need to be kept in mind such as the language of the website, the User Interface & Design etc
Some time developers leave comments in the source code which can be analyzed to gather more information about the target. External and Internal links can be used to link information together.
In this section, we are instructed to navigate to a link and find out the following
Number of internal links in the text of the article
5
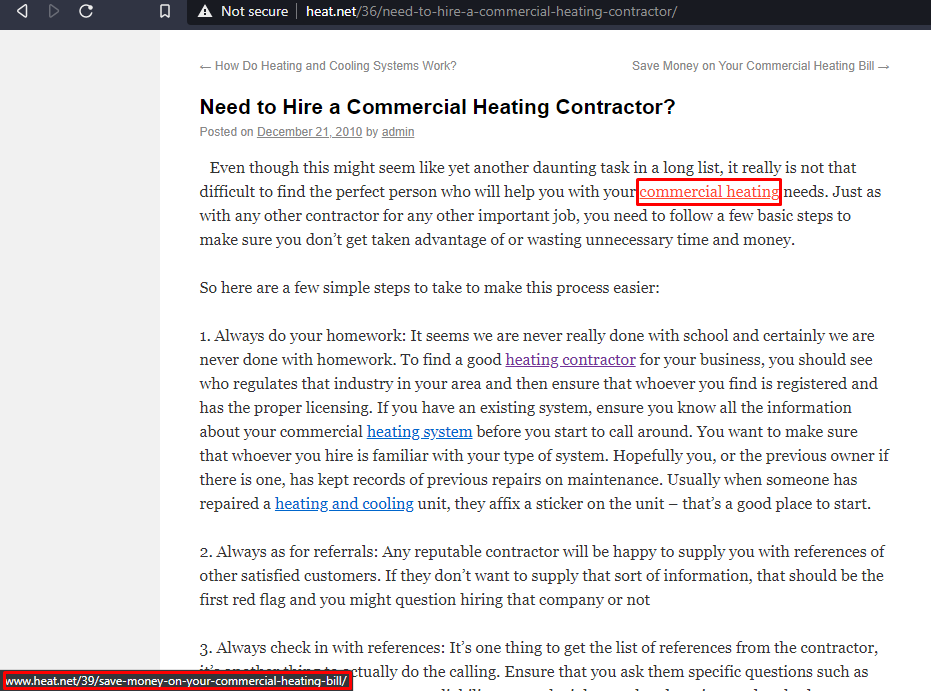
Number of External Link in this article
1
External Link URL
purchase.org
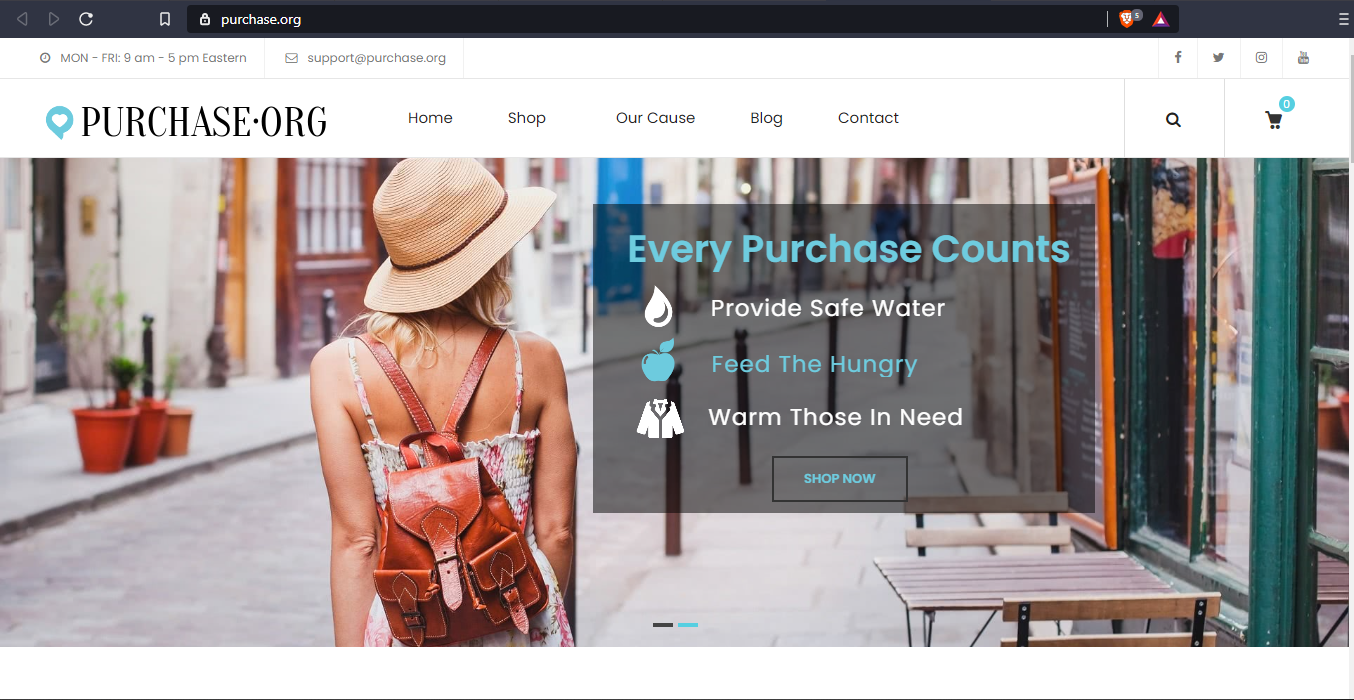
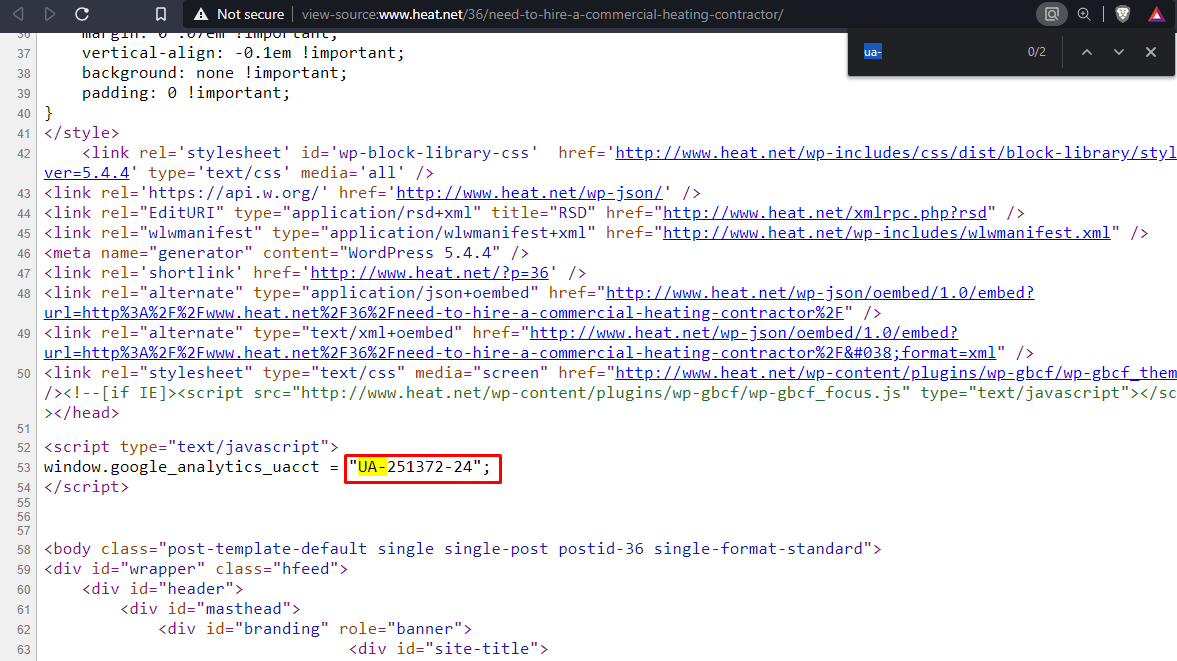
Google Analytics code linked to the site
Use the view page source on the article and find the google analytics code as seen below
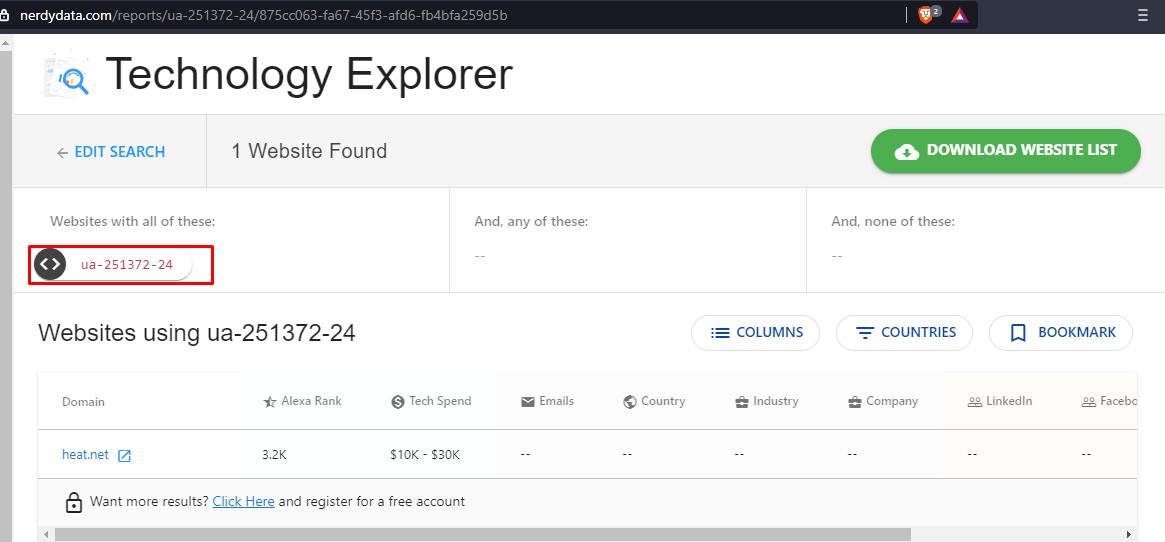
In order to find out wether this google analytic code is being used on any other website use nerdydata.com. This online tool will search through webpages and tell us if the query is found in any other websites
We don't find any affiliate links to the website. We can look at the contents of href to find such links.
Task 7
Final Exam: Connect The Dots
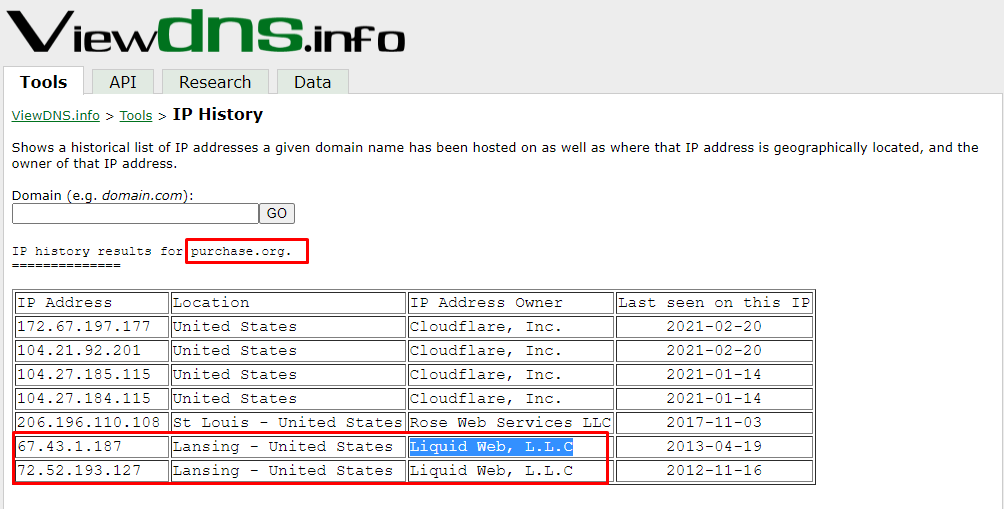
In this task, we need to find a connection between our target site i.e. heat.net and the external link. There is no affiliate link associated with the website that could generate income to the business then what could be the connections. Let's find out. We revisit the IP history tool and find out that the external link(purchase.org) domain has the same owner as that of heat.net.
Wrapping Up
In the previous section, we found out that both of the websites are under the same ownership. When we look at heat.net we don't find the site very interesting or appealing nor does it generates that much traffic that would benefit the owner while on the other hand purchase.org is an e-commerce website and probably generates revenue more than heat.net. What we can conclude from here is that the owners are running a private blog network(PBN), to convince the search engines to rank their main website to a higher rank. Heat.net is just baited to trick the search engine into the ranking purchase.org to higher ranks.
About Me
I am a Network Security Engineer pursuing my Master’s in Information Security and trying to get into a full-time cybersecurity career. You can follow for more write-ups and walkthroughs here.
